
 abonnieren
abonnieren
 verfolgen
verfolgen


In dieser Aufzeichnung stellen wir Ihnen Verbesserungen und Neuerungen der Version 6.3 von ![]() GeNiEnd2End vor.
GeNiEnd2End vor.
Dies sind einige davon:
- Verbessertes Notification System und Filtermöglichkeiten
- Möglichkeiten neuer inkludierter Skripte
- VoIP-Tests für Microsoft Teams & Skype
- Effizienteres Updaten der GeNiJacks durch Nutzungen des neuen Update Hubs
- Realisierung und Auswirkungen der verbesserten Performance
- Details der Sicherheitsupdates
- Kombination von Allegro Packets Network Multimeter und NETCOR GeNiEnd2End
Sollten Sie dazu Fragen haben, eine neue Lizenzdatei oder Unterstützung bei dem Update benötigen, melden Sie sich gerne bei uns:
+49 4181 9092-110
support@netcor.de
Grundsätzlich sind zahlreiche Cybergefahren ebenso bekannt wie verwendete Tools und das Vorgehen von Hackern, mit dem sie Netze infiltrieren, Clients infizieren und Daten verschlüsseln. Damit ein Angriff auf die eigene Infrastruktur allerdings auch „rechtzeitig“ erkannt und anschließend erfolgreich abgewehrt werden kann, benötigt man ein darauf spezialisiertes Werkzeug der Gattung Network Detection and Response.
Wir zeigen Ihnen in diesem Webinar, wie ![]() ExeonTrace mit Hilfe von Machine Learning und Kl zuverlässig Cybergefahren erkennt. Diese Zuverlässigkeit beinhaltet auch, dass ExeonTrace False Positives deutlich reduziert und damit das Security-Team nicht unnötig belastet.
ExeonTrace mit Hilfe von Machine Learning und Kl zuverlässig Cybergefahren erkennt. Diese Zuverlässigkeit beinhaltet auch, dass ExeonTrace False Positives deutlich reduziert und damit das Security-Team nicht unnötig belastet.
Ein NDR kann und soll EDR nicht ersetzen. Wir erläutern, wie Sie EDR, NDR und SIEM sinnvoll miteinander kombinieren. Zusätzlich geht es darum, wie sich ExeonTrace in die komplette Infrastruktur, also auch in Legacy Systeme, integrieren lässt.
Wenn Sie ExeonTrace näher kennenlernen wollen, melden Sie sich bitte telefonisch oder über das ![]() Kontaktformular bei uns.
Kontaktformular bei uns.
Geht es darum, bei Problemen mit der Anwendungsperformance oder zur Bewertung der Kommunikationen im Netzwerk eine Aussage zu treffen, werden Datenpakete analysiert. Auf Seiten der Security gibt es in Form von IDS oder ![]() NDR ebenfalls Tools, die auf Datenpakete angewiesen sind.
NDR ebenfalls Tools, die auf Datenpakete angewiesen sind.
Der kürzeste Weg, diese Daten aus dem Netzwerk abzugreifen ist der SPAN-Port. Nachteil ist, dass SPAN-Ports nicht für den 24/7-Betrieb gedacht sind und auch weitere Schattenseiten aufweisen: Bei ![]() Performance-Analysen ist zu beachten, dass Pakete recht schnell verloren gehen können oder in falscher Reihenfolge eintreffen. Defekte Pakete werden gar vollständig unsichtbar, sie werden schlicht verworfen.
Performance-Analysen ist zu beachten, dass Pakete recht schnell verloren gehen können oder in falscher Reihenfolge eintreffen. Defekte Pakete werden gar vollständig unsichtbar, sie werden schlicht verworfen.
Aus Sicherheitssicht ist ein SPAN-Port ebenfalls keine optimale Idee, er stellt aufgrund des Vorhandenseins von Empfangs- aber auch Senderichtung ein Risiko dar.
Wir zeigen Ihnen in diesem Webinar detailliert, weshalb der Einsatz von TAPs oder auch Daten-Dioden vorteilhaft ist. Dabei gehen wir darauf ein, was für Arten von TAPs es gibt und wie sie im Zusammenspiel von ![]() TAPs und Network Packet Broker Switchen sehr effizient und flexibel viele Messpunkte einrichten können.
TAPs und Network Packet Broker Switchen sehr effizient und flexibel viele Messpunkte einrichten können.
Die Datenpakete können sie anschließend aufbereiten, aggregieren und weiterleiten. In vielen Fällen lassen sich dadurch Kosten für Analysegeräte & Lizenzen reduzieren.
Für jeden Security-Verantwortlichen ist die gestiegene Professionalität, mit der sich Hacker durch Cyberattacken Zutritt in fremde Netze verschaffen wollen, zu einer großen Herausforderung geworden. Auch wenn die Basics wie Virenschutz, IDS/IPS und EDR-Lösungen, längst im Einsatz sind, insbesondere bei komplexen Angriffen sind sie nicht ausreichend.
Ein entscheidender Nachteil der vorgenannten Lösungen ist, dass ihre Stärke in der Erkennung von längst bekannten Angriffen liegt und für die es Erkennungssignaturen gibt. Bei gänzlich neuen Attacken sind sie regelmäßig wirkungslos. Zusätzlich lässt sich zum Beispiel auch nicht auf jedem Device ein EDR installieren.
Einen äußerst wirkungsvollen Ausweg aus diesem Sicherheits-Dilemma gegen bislang unbekannte Unbekannte stellt der Einsatz einer Network Detection and Response Lösung dar.
Grundlegende Annahme dieses Ansatzes ist, dass keine Cyber-Attacke auf die Nutzung des Netzwerks verzichten kann. Der vorhandene Netzwerkverkehr wird vom NDR protokolliert und anschließend analysiert.
Wie NDR in IT, IoT und OT implementiert wird und wie Sie damit zuverlässig Anomalien im Netzwerkverkehr und somit potentielle Sicherheitsvorfälle erkennen können, zeigen wir Ihnen in diesem Video.
Wenn Sie ExeonTrace näher kennenlernen wollen, melden Sie sich bitte ![]() telefonisch oder über das
telefonisch oder über das ![]() Kontaktformular bei uns.
Kontaktformular bei uns.

Das Konzept der automatischen Reaktion (Automatic Response) in Network Detection & Response (NDR) Lösungen zielt darauf ab, Cyberbedrohungen schnell und präzise abzuwehren, ohne auf menschliches Eingreifen angewiesen zu sein.

NDR-Systeme können automatische Reaktionsfunktionen einsetzen, wie beispielsweise das Versenden eines TCP-Resets an potenziell kompromittierte Systeme, um die Verbindung zu externen Bedrohungsquellen zu unterbrechen. Ebenso ist es möglich, kompromittierte Geräte in separaten Netzwerksegmenten zu isolieren.
Trotz der anfänglichen Begeisterung für solche Technologien gibt es nachvollziehbare Gründe, die gegen eine ausschließliche Automatisierung sprechen und die Bedeutung bewährter Prozesse mit manueller Intervention betonen:
- Herausforderungen bei der Integration: Die Integration des NDR-Systems mit heterogener Netzwerkinfrastruktur kann kompliziert sein. Veränderungen wie Updates, Patches oder Konfigurationsänderungen können unvorhergesehene Auswirkungen haben.
- Ausnahmeregelungen: Unerfasste oder undokumentierte Ausnahmen führen zu Inkonsistenzen. Dies birgt das Risiko, dass die automatische Reaktion nicht wie beabsichtigt funktioniert.
- Fehlalarme und Fehlfunktionen: Fehlerhafte automatische Reaktionen gefährden die Sicherheit und Effizienz. Automatische Isolierung kann den Geschäftsbetrieb beeinträchtigen, insbesondere bei kritischen Systemen.
- Compliance und rechtliche Aspekte: Automatische Reaktionen könnten Compliance verletzen, je nach Branche und Vorschriften.
Eine sorgfältige Planung, Konfiguration und Überwachung von automatischen Reaktionen in NDR ist unerlässlich, um potenzielle Nachteile zu minimieren. Die Herausforderung liegt oft in der durchschnittlichen Fehlalarmrate pro Tag. Solche Fehlinterpretationen von Ereignissen können zu unnötiger Isolierung von Geräten führen.
Um diese Risiken zu minimieren, ist es wichtig, dass automatische Response-Systeme sorgfältig konfiguriert und insbesondere bei Änderungen ausführlich getestet werden. Es sollten klare Richtlinien und Prozesse für die Überprüfung und Freigabe von Isolierungen im Falle eines Fehlalarms vorhanden sein.
Unter Berücksichtigung dieser Faktoren zeigt sich häufig, dass die Erweiterung bestehender Prozesse zur effizienten Bewältigung von Sicherheitsalarmen in Kombination mit fortschrittlichen NDR-Systemen, eine sinnvolle Alternative darstellt. Besonders, wenn die Umsetzung und der Betrieb automatischer Reaktionen als ressourcen- und zeitintensiv erscheinen.
In der abschließenden Episode unserer Reihe „Der Nutzen von Network Detection and Response in IT, IoT und OT“ geht es um Machine Learning in der Cyber-Security. Generell taucht KI und auch seine Teildisziplin ML im IT-Alltag regelmäßig auf. Der konkrete Mehrwert durch ML und wie er erreicht wird, bleibt dabei jedoch häufig unklar.
Wir zeigen Ihnen in diesem Webinar worin der Vorteil der Benutzung von ML liegt und wie sich supervised Machine Learning und unsupervised Machine Learning in Funktionsweise und Nutzen unterschieden.
Zusätzlich stecken wir mit Ihnen ab, bei welchen unterschiedlichen Bedrohungen Machine Learning und Signaturen/IoC die jeweiligen Stärken ausspielen können.
Wenn Sie ExeonTrace näher kennenlernen wollen, melden Sie sich bitte telefonisch oder über das ![]() Kontaktformular bei uns.
Kontaktformular bei uns.
Im dritten Teil unserer Reihe „Der Nutzen von Network Detection and Response in IT, IoT und OT“ geht es insbesondere um die Besonderheiten der Security im OT-Umfeld.
Anhand einer Beispielarchitektur zeigen wir Ihnen, welche Bedrohungen es konkret gibt und wodurch diese begünstigt werden. In dem Zusammenhang gehen wir natürlich auch auf die Purdue Reference Architecture ein.
In einem Szenario gehen wir zusammen durch, zu welchen Zeitpunkten ![]() ExeonTrace eine Bedrohung detektiert. Da leider auch Network Detection and Response keine Eierlegende Wollmilchsau ist, zeigen wir auf, wo ein NDR prinzipbedingt in der Erkennung Grenzen hat.
ExeonTrace eine Bedrohung detektiert. Da leider auch Network Detection and Response keine Eierlegende Wollmilchsau ist, zeigen wir auf, wo ein NDR prinzipbedingt in der Erkennung Grenzen hat.
Im finalen Teil unserer Reihe „Datenpakete effizient analysieren“ ist Wireshark mit den Erkenntnissen der vorherigen Episoden richtig konfiguriert und der Datenverkehr wird mittels TAPs und ggf. NPBS passend eingesammelt, vorgefiltert und weitergeleitet. Somit sind alle Vorbereitungen getroffen, um über die benötigte Transparenz zu verfügen.
Wir zeigen Ihnen, wie Sie selbst mit richtig vielen Daten über eine mächtige Suche sehr, sehr schnell im Troubleshooting Fall den Fokus auf die relevanten Pakete legen können. Zum Ausschließen von Segmenten und damit Eingrenzen von Problem-verursachenden Segmenten ist eine Strecken-/Zangenmessung mit mehreren Messpunkten sehr effizient. Am Live System vom Allegro Network Multimeter gehen wir mit Ihnen durch, wie Sie ausgesprochen unkompliziert zwei Tracefiles gegeneinander abgleichen können.
Vom ![]() Allegro Network Multimeters können natürlich auch externe Tracefiles, die zum Beispiel mit
Allegro Network Multimeters können natürlich auch externe Tracefiles, die zum Beispiel mit ![]() Wireshark oder einem
Wireshark oder einem ![]() EtherScope erstellt wurden, analysiert werden.
EtherScope erstellt wurden, analysiert werden.
Der fünfte Teil unserer Reihe „Datenpakete effizient analysieren“ widmet sich einem Security-Thema. Es geht darum, wie man Datenpakete aus kritischen Netzen sicher an IDS und ![]() NDR weiterleiten kann.
NDR weiterleiten kann.
Naheliegend ist dabei für viele die Benutzung eines vorhandenen Span-Ports. Wir zeigen, wieso das insbesondere KRITIS-Betreiber unterlassen sollten. Dabei geht es um die technische Unsicherheit aber auch um die "Chance", über einen Span-Port nicht alle Pakete für Analysezwecke zu erhalten.
Damit das Webinar auch einen konstruktiven Charakter erhält, stellen wir Ihnen mit Daten-Dioden, Taps und Network Packet Broker Switches Alternativen vor, die aus Sicherheits- und Funktionssicht deutlich besser sind.
In der vierten Episode unserer Reihe „Datenpakete effizient analysieren“ geht es um die Möglichkeiten, mehrere Messpunkte mit Aggregation TAPs oder Network Packet Broker Switches effizient zu nutzen. Dabei stellen wir Ihnen vor, welche Optionen Ihnen bei der Verteilung der Daten auf mehrere Analysetools für Performance und Security zur Verfügung stehen.
Wir gehen auch darauf eine, worauf man bei Duplicate Packets mit einem Network Packet Broker Switch achten muss und wie man Packet Deduplication mit Wireshark und weiteren Analysetools handhabt.
Im zweiten Teil unserer Reihe „Der Nutzen von Network Detection and Response in IT, IoT und OT“ stellen wir Ihnen das typische Vorgehen eines Angreifers anhand der Cyber Kill-Chain vor.
Dabei gehen wir auch darauf ein, welche Netzwerkdaten einen Angreifer in der jeweiligen Phase verraten.
Wichtig ist dabei zu wissen, dass die einzelnen Schritte für sich genommen so unauffällig sind, dass sie ohne ein NDR wie ![]() Exeon Trace nicht erkannt werden würden.
Exeon Trace nicht erkannt werden würden.
Abgerundet wird das Webinar mir einer Live-Demo, in der gezeigt wird, wie ein Cyber-Angriff konkret erkannt wird.
Der dritte Teil unserer Reihe „Datenpakete effizient analysieren“ beschäftigt sich mit der Frage, wie Messdaten zuverlässig in einen Analyzer gelangen. So banal die Aufgabenstellung klingen mag - geschieht hier ein Fehler im Messaufbau, sind meist alle weiteren Analyseschritte wertlos.
Mit diesem Wissen im Hinterkopf beleuchten wir den im ersten Gedankengang plausibelsten Weg der Datenausleitung: Den Span-Port. Dabei erläutern wir, wenn denn im jeweiligen Fall möglich, wie man den Span-Port richtig benutzt.
Die aus technischer Sicht schönste Lösung stellen für Kupfer und Glas verfügbare TAPs dar. Diese zeigen wir Ihnen ausführlich.
Abgerundet wird das Webinar mit einer detaillierten Definition von Last und den Möglichkeiten, sie falsch zu interpretieren. Hier spielen Microbursts eine große Rolle.
Bei dem Auftakt unserer Reihe „Der Nutzen von Network Detection and Response in IT, IoT und OT“ zeigen wir Ihnen, wie Network Detection and Response einen Baustein der Security-Architektur eines Unternehmens darstellt.
Dabei gehen wir darauf ein, wie mit Hilfe von Kommunikationsanalysen Angriffe in IT, IoT sowie OT automatisch erkannt und dann auch schnell analysiert werden können.
Ein wichtiger Punkt ist dabei das Thema Machine Learning. Auch wenn ML mittlerweile ein arg gestresster Begriff ist: In ![]() Exeon Trace ist ML integriert und hilft effizient bei der Erkennung von Anomalien und der Reduzierung von False Positive Alarmen.
Exeon Trace ist ML integriert und hilft effizient bei der Erkennung von Anomalien und der Reduzierung von False Positive Alarmen.
Thema des zweiten Teils unserer Reihe „Datenpakete effizient analysieren“ ist das mobile Troubleshooting ohne Kompromisse.
Am Anfang einer jeden Paketanalyse steht das Capturen von Paketen. In dem Webinar gehen wir darauf ein, wieso in vielen Fällen PC, Laptop und auch ein SPAN-Port für eine fehlerfreie Aufzeichnung von Datenpaketen nicht geeignet ist.
Anhand von ![]() ProfiShark,
ProfiShark, ![]() IOTA und
IOTA und ![]() Allegro Network Multimeter zeigen wir Ihnen, wie Sie im IT- und OT-Umfeld effizient capturen, filtern und analysieren können.
Allegro Network Multimeter zeigen wir Ihnen, wie Sie im IT- und OT-Umfeld effizient capturen, filtern und analysieren können.
Für den Fall, dass Sie gerne Ihre Wireshark-Kenntnisse ausbauen wollen, bieten wir Ihnen dazu eine ![]() Schulung an.
Schulung an.
Im ersten Teil unserer Troubleshooting-Reihe „Datenpakete effizient analysieren“ geht es darum, wie und wann man Wireshark einsetzen sollte, um mit vertretbarem Aufwand ein Problem analysieren zu können.
Dabei zeigen wir Ihnen auch, wie ein Messaufbau für eine zuverlässige Messung im Optimalfall aussieht und welche Einstellungen in Wireshark vorgenommen werden müssen, um überhaupt sinnvoll Daten damit aufzeichnen zu können.
Für den Fall, dass Sie gerne Ihre Wireshark-Kenntnisse ausbauen wollen, bieten wir Ihnen dazu eine ![]() Schulung an.
Schulung an.
Wireshark 4 hat einige Detailverbesserungen erhalten. Dazu gehören zum Beispiel umfangreichere Filtermöglichkeiten sowie verbesserte Konversationsstatistiken. Anhand von Praxisbeispielen zeigen wir Ihnen, wann und wie Ihnen diese Verbesserungen das Arbeiten mit Wireshark vereinfachen.
Zusätzlich gehen wir auf Änderungen der Benutzeroberfläche ein und wie dadurch der Workflow verbessert werden kann.
Falls Sie Wireshark-Kenntnisse aufbauen oder verbessern wollen, können Sie gerne für eine ![]() Schulung auf uns zu kommen.
Schulung auf uns zu kommen.
Die Übertragung von Sprache über das IP-Protokoll birgt sowohl in Unternehmensnetzen als auch im Providerumfeld diverse Herausforderungen. So gibt es zunächst eine sehr hohe Verfügbarkeitsanforderung. Als Echtzeitdienst bemerken die Nutzenden aber auch sofort Probleme in der Dienstgüte. Gerade die Netzwerkqualitätsparameter Paketverlust, Jitter und Delay haben einen großen Einfluss auf die resultierende Sprachqualität.
Grundsätzlich ist im VoIP-Umfeld zu beachten, dass man zwischen drei Datenströmen differenziert, wobei nur zwei einen bemerkbaren Einfluss für die Nutzenden hat.
- Den ersten Datenstrom stellt die Signalisierung dar. Als Signalisierung bezeichnet man die Kommunikation zum Auf- und Abbau, sowie Änderungen. Dabei werden auch schützenswerte Metadaten, wie Quell- und Zielrufnummer übertragen. Es gibt unterschiedliche Protokolle zur Signalisierung, wie SIP (Session Initiation Protocol), H.323 oder MGCP (Media Gateway Control Protocol). Im öffentlichen Netz und aktuellen Unternehmensnetzen kommt primär das SIP-Protokoll zum Einsatz. Es gibt jedoch eine Vielzahl von unterschiedlichen SIP-Implementierungen. Dies führt in der Praxis zu vielfältigen Fehlerquellen durch Inkompatibilitäten. Im Payload der Signalisierung, genauer gesagt im Session Description Protocol (SDP) werden aber auch einige Parameter, wie zu verwendende Codecs und die UDP-Ports, sowie die zugehörigen IP-Adressen für die Sprachdatenübertragung ausgehandelt.
- Den zweiten Datenstrom stellt die Übertragung der Sprache über das Real-Time Transport Protocol (RTP) dar. Dieses Protokoll basiert auf einer UDP-Übertragung und es ist als Echtzeitübertragung besonders sensitiv gegenüber Latenz, Jitter und Paketverlusten. Es können Hierbei unterschiedliche Codecs mit unterschiedlichen Paketierungszeiten, Größe und Qualität zum Einsatz kommen.
- Den dritten Datenstrom stellt das Real-Time Transport Control Protocol (RTCP) dar. Er liefert statistische Daten mit Qualitätsindikatoren für VoIP. Dieser Datenstrom fließt auf gleichem Transportweg wie RTP, jedoch eine Portnummer höher.
Eine große Herausforderung beim Troubleshooting in VoIP-Umgebungen stellt die Differenzierung der Fehlerursache zwischen Signalisierung und Sprachdaten oder auch dem zugrunde liegenden Netzwerk dar. Die unterschiedlichen Medienströme müssen in vielen Fällen auch NAT-Übergänge oder auch Sicherheitskomponenten, wie Firewalls passieren. Dies führt in der Praxis dazu, dass sich die zuständigen Teams für VoIP, Netzwerk und Sicherheit bei Fehlern die zugehörigen Tickets hin- und herschieben. Das Profitap IOTA hat es sich zur Aufgabe gemacht, die VoIP-Analyse effektiv und effizient zu machen. Das „Blame Game“ zwischen den unterschiedlichen Teams soll durch grafisch aufbereitete Dashboards in Kombination mit vielfältigen Filteroptionen für SIP und RTP ein Ende haben und für den Endanwender die Mean-Time-to-Recover (MTTR) durch eine schnelle Fehleranalyse verkürzen. Dienstanbieter können somit auch Ihre SLAs besser einhalten.

Root Cause Analyse
Die Root Cause Analyse in VoIP Netzen gleicht häufig der Suche nach der Nadel im Heuhaufen. Von den Anwendern kommen meist recht unstrukturierte Fehlermeldung, wie „Mein Telefon funktioniert seit gestern nicht mehr. Ich erhalte immer ein Besetzt-Zeichen.“ oder „Ich habe zeitweise Verständigungsprobleme mitten im Gespräch.“. Ob dies am Netzwerk, einer Firewall, einem Signalisierungsfehler auf einem SIP-Proxy oder einem Fehler der Endgeräte liegt, kann zunächst nur schwierig differenziert werden. Aber auch einseitige oder gar keine Verständigung (One Way Audio oder Dead Air Effekt), sowie zeitweise abbrechende Anrufe stellen eine Herausforderung im Troubleshooting Prozess dar.
Es gilt also die grundsätzliche Ursache des Problems (Root Cause) zu ermitteln. Wenn die Key Performance Indikatoren Paketverlust, Jitter und Delay bidirektional ohne Auffälligkeiten sind, kann ein Sicherheits- und Netzwerkproblem ausgeschlossen werden. Die Ursache kann dann direkt im VoIP-Umfeld gesucht werden. Jedoch ist nicht jede VoIP-Verbindung direkt Ende-zu-Ende messbar. Sogenannte Session Border Controller (SBC) können an Sicherheitsübergängen den SIP-Dialog und den RTP-Datenstrom je Kommunikationsseite terminieren und manipulieren. Es kann also geschehen, dass trotz gemessenen Paketverlusten von 0% bis zum Provider hinter dessen SBC ein Paketverlust zu einem anderen Provider besteht. Somit sind VoIP Analysen auch häufig an multiplen Punkten im Netzwerk durchzuführen.
Im VoIP-Umfeld selbst muss zunächst definiert werden, ob es sich um ein Problem in der Signalisierung oder im Sprachdatenstrom handelt. Kommt es beim Verbindungsauf- oder Abbau oder einer Veränderung, wie einem Halten des Gesprächs oder einem Codecwechsel zu Problemen, liegt dies an einem Signalisierungsproblem und es kann gezielt in den SIP-Daten über Filter eine Eingrenzung
geschehen.
Schwieriger in der Analyse sind die bereits erwähnten Fehlerbilder, wie Dead Air und One Way Audio. Diese können sowohl aus dem Netzwerk kommen, aber auch durch Firewalls und IPS-Systeme oder Probleme in Baugruppen des VoIP-Systems. Beispiel für einen Netzwerkfehler wäre ein fehlerhaftes Routing oder ein NAT-Übergang. Problem bei NAT im Zusammenhang mit VoIP ist, dass lediglich die IP-Informationen im Header ersetzt werden, jedoch nicht im Payload. SIP überträgt jedoch im Session Description Protocol (SDP) IP- und Portinformationen für den RTP-Stream. Wenn nun ein NAT-Übergang die IP-Header manipuliert, aber im Payload keine Anpassung vollzogen wird, führt dies zu einseitiger oder keiner Verständigung, da der RTP-Datenstrom zum falschen Ziel geführt wird. Gleichzeitig besteht aber auch die Möglichkeit, dass eine Firewall die Ports für die Signalisierung zulässt, aber den RTP-Datenstrom blockt. Aber auch Intrusion Prevention System bieten eine mögliche Fehlerquelle für geblockte RTP-Datenströme. Gleichzeitig könnte dies jedoch auch im VoIP-Umfeld an einer nur einseitigen Verschlüsselung mit SRTP oder einem fehlerhaften Codecwechsel oder defekten VoIP-Baugruppen, wie DSPs liegen. Es braucht also für die Root Cause Analyse ein Werkzeug, dass flexibel an unterschiedlichen Stellen im Netzwerk zum Einsatz kommen kann und mit einfachen Mitteln einen „Drill Down“ auf die benötigten Informationen ermöglicht.
Wie kann Profitap IOTA unterstützen?
Das ![]() Profitap IOTA bietet eine portable Lösung zur VoIP Analyse. Damit eignet es sich, um an unterschiedlichen Stellen im Netzwerk aufzuzeichnen und zu analysieren. Sowohl der Betrieb im Inline-, als auch im SPAN-Modus sind möglich. Somit ist es in der VoIP Analyse flexibel einsetzbar, da es sowohl zwischen Telefon und Switch im Inline Betrieb geschaltet werden kann, aber auch direkt an einem SPAN-Port des Switches, wenn beispielsweise ganze VLANs oder ein Switchport zu einem Session Border Controller oder einer IP-PBX analysiert werden müssen.
Profitap IOTA bietet eine portable Lösung zur VoIP Analyse. Damit eignet es sich, um an unterschiedlichen Stellen im Netzwerk aufzuzeichnen und zu analysieren. Sowohl der Betrieb im Inline-, als auch im SPAN-Modus sind möglich. Somit ist es in der VoIP Analyse flexibel einsetzbar, da es sowohl zwischen Telefon und Switch im Inline Betrieb geschaltet werden kann, aber auch direkt an einem SPAN-Port des Switches, wenn beispielsweise ganze VLANs oder ein Switchport zu einem Session Border Controller oder einer IP-PBX analysiert werden müssen.
Neben der reinen Aufzeichnung bietet das IOTA jedoch auch applikationsseitige Analysefunktionen für VoIP. Somit kann dem Fingerpointing zwischen Netzwerk- und Voice-Team schnell ein Ende gesetzt werden. Netzwerkadministratoren können für definierte Zeiträume oder sogar einen spezifischen Anruf Paketverluste und Jitter erkennen. Dies kann über eine Filterung auf die Quell- oder Ziel-URI des Anrufers geschehen. Abbildung 2 bietet ein Beispiel eines Filters auf die Ziel-URI. Übergibt der VoIP-Administrator sogar die Call-ID des Anrufs, kann direkt eine Filterung auf den Anruf stattfinden. So kann der Fehler soweit vorqualifiziert werden, dass im Nachgang gezielt auf einzelnen Netzwerkkomponenten, wie Switches und Routern auf Link-Fehler und Quality of Service Probleme gesucht werden kann.

Für Qualitätsprobleme in der Übertragung der Sprachdaten im RTP-Datenstrom bietet das IOTA vielfältige Möglichkeiten. So gibt es ein vorbereitetes Call Detail Dashboard, dass jeweils von Anrufendem und Angerufenen separiert den Jitter und Paketverluste angibt. Die Anzeige von Paketverlusten gibt die Werte sowohl prozentual zu der Gesamtanzahl an Paketen an, als auch in der reinen Menge an Paketen, die verloren wurden. Neben den übersichtlichen Grafiken bieten sich auch Filter mit „>=“ an. So können Anrufe mit Paketverlusten und Jitter über bestimmten Schwellwerten, wie beispielsweise Jitter >= 20ms herausgefiltert werden.

Aber auch das „Click-and-Drag“ in den Grafiken bietet die Möglichkeit, bei festgestellten Auffälligkeiten, gezielt in einen Zeitbereich zu springen. Ein Einfaches „Click-and-Drag“ mit der Maus genügt dabei, um den Zeitbereich einzuschränken. Erkennt der Netzwerkanalyst einen hohen prozentualen Anteil des Paketverlusts im Vergleich zu den übertragenen Paketen im Call Detail Dashboard, kann er die Call-IDs erkennen und diese in Filtern nutzen, um problematische Kommunikationsbeziehungen zu erkennen. Führt die Analyse eines Dead Air Effekts beispielsweise immer wieder zu einem bestimmten Portbereich könnte eine fehlende oder nicht ausreichende Firewallfreigabe ursächlich sein.
Dies bietet die Möglichkeit Tickets zu Verständigungsproblemen in der VoIP-Umgebung schnell vorqualifizieren zu können. Das IOTA ermöglicht es durch vielfältige Filtermöglichkeit, den Fehler immer näher einzugrenzen, um zum „Root Cause“ des Problems zu kommen.
Aber auch im Bereich von Signalisierungsfehlern kann das IOTA einiges bieten. Um Muster von Signalisierungsfehlern erkennen zu können, bietet sich die in Abbildung 4 dargestellte Grafik „SIP Methods and Responses“ aus dem VoIP Dashboard an. Falls vermehrt „488 Not acceptable here“ sichtbar wären, würde dies beispielsweise auf eine Inkompatibilität der Codecs hindeuten. Bei „403“ Fehlercodes hingegen, dass der SIP-Proxy die Anfrage ablehnt.
Bei vermehrten „404 Not found“ Meldungen kann man gezielt einen Blick auf die Callee URIs im VoIP Dashboard werfen, um die fehlerhaften Zielrufnummern oder Zieldomains zu erkennen. Im Beispiel in Abbildung 4 sind einige 403 Responses sichtbar. Diese sind in der eingesetzten SIP-Authentifizierung begründet und somit vollkommen in Ordnung.

Bei einem verzögerten Gesprächsaufbau könnten auch die Latenzdaten der Signalisierung einen Aufschluss bringen. Bei SIP über TCP bietet die Round-Trip-Time einen ersten Ansatzpunkt. Diese kann das IOTA ebenfalls analysieren.
Für komplexere Fälle können auch gezielt PCAP-Daten heruntergeladen werden, um diese näher in Wireshark zu analysieren. So können bei unverschlüsseltem RTP und unterstütztem Codec auch die aufgezeichneten Audioinhalte im RTP-Player angehört werden, um sich unabhängig vom Telefon einen Eindruck von der Sprachqualität zu verschaffen. Sogar ein automatisierter Export von PCAP-Dateien auf eine externe Datenquelle ist möglich.

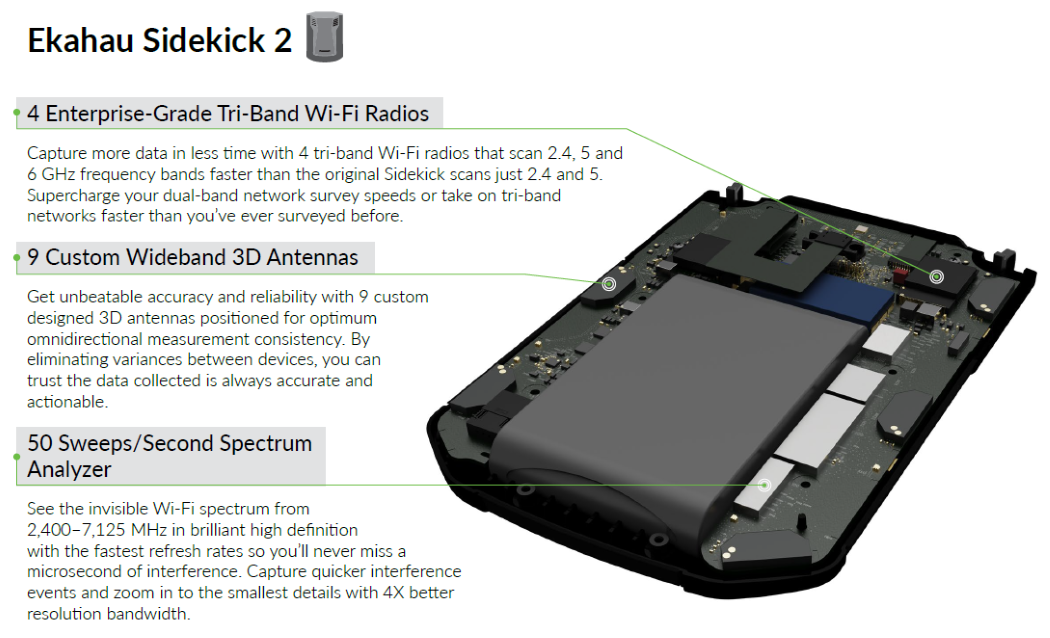
Nach 5 Jahren und einem neuen Frequenzspektrum (6GHz), was für WLAN die Zukunft werden kann, war es auch mal an der Zeit, dass etwas Neues kommt.
Mit dem Launch-Event am 21.07.2022 wurde der Sidekick 2 umfassend vorgestellt. Der Sidekick 2 ist ab sofort bestellbar und es gibt auch wieder eine Option für die Verlängerung der Hardware-Garantie auf 3 Jahre. Eine Möglichkeit zum Trade In für Sidekick 1 bietet Ekahau leider nicht an.
Der Sidekick 1 wird jedoch weiterhin in vollem Umfang unterstützt, die Firmware wird weiterentwickelt und er ist auch weiterhin ein toller Messbegleiter.
Ekahau hat mit dem Sidekick 2 auf seine Kunden gehört und einige Wünsche beachtet und Probleme beseitigt.
Was ist neu?
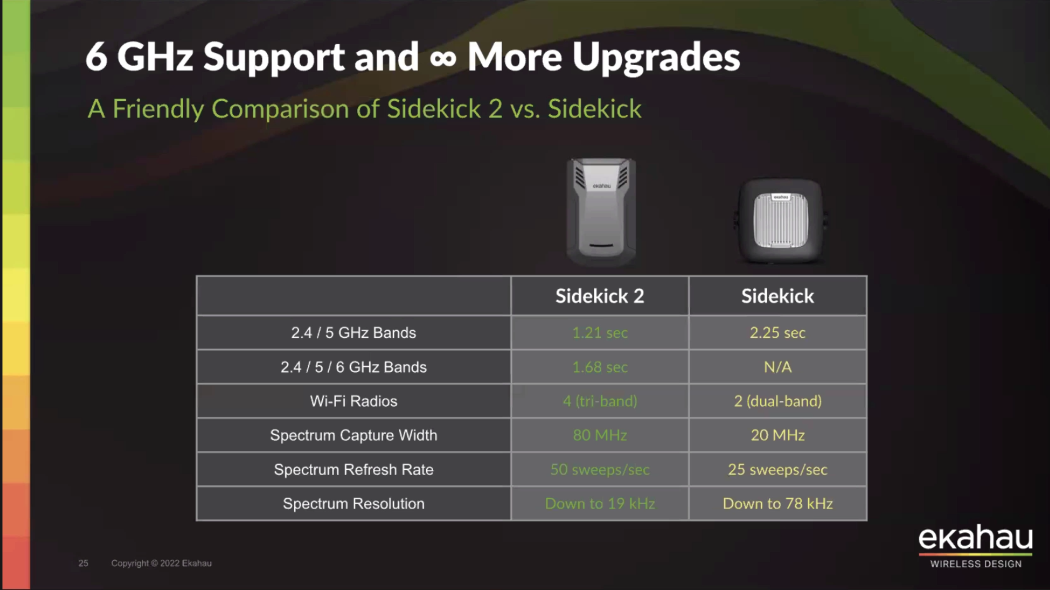
- Vier integrierte Tri-Band (2.4/5/6GHz) WLAN-Adapter
- Stark verbesserter Spektrum-Analysator mit 50 Sweeps und 19kHz Auflösung
- Deutlich größerer Akku erlaubt bis zu 16 Stunden Surveys am Stück
- 1 Stunde Schnellladen = 4 Stunden Survey
- Endlich ein USB-C-Anschluss mit Zugentlastung - damit die Anschlüsse nicht mehr kaputt gehen
- Die Messgenauigkeit wurde deutlich erhöht
Die vier WLAN-Adapter sammeln entschieden mehr Daten und sind beim Scannen aller drei Frequenzspektren schneller als der Sidekick 1 mit zwei Frequenzspektren. Die Antennen wurden ebenfalls komplett überarbeitet und speziell für Ekahau entwickelt, um eine noch bessere und präzisere Aufzeichnung von Messdaten zu ermöglichen.
 |
 |
 |
| Ekahau Sidekick 2 | Vergleich Sidekick 2 vs 1 - Scannen | Vergleich Sidekick 2 vs 1 - Antennen |
Für alle Infos schauen Sie doch mal auf unsere neue ![]() Sidekick 2-Produktseite.
Sidekick 2-Produktseite.
Einen Blogeintrag von Ekahau mit ausführlichen Infos und Videos gibts hier:
![]() Introducing Ekahau Sidekick 2 - Essential for High-Performing Wi-Fi
Introducing Ekahau Sidekick 2 - Essential for High-Performing Wi-Fi
Um schnell eine Übersicht über den Status und die Performance Ihrer GeNiEnd2End-Umgebung zu bekommen, bieten wir schon länger die Möglichkeit an, Daten per SNMP / WMI oder die vom GeNiEnd2End Server integrierte JSON API abzufragen.
Welche Daten gesammelt werden können und in welchem Umfang, das wollen wir hier erläutern.
Warum sollte man überhaupt ein Network Performance / Application Monitoring Tool überwachen?
- Nicht jeder hat Zugriff auf GeNiEnd2End oder kennt sich damit aus, möchte aber den Status seiner Tests und Agenten sehen.
- Oft werden andere Monitoring Tools umfangreicher genutzt (z.B. PRTG) und diese können auch Daten von Ihrer GeNiEnd2End-Umgebung anzeigen.
- Ein leicht verständliches Dashboard für zum Beispiel externe Standorte, den Helpdesk oder Vorgesetzte kann einfach den Status Ihrer IT-Umgebung anzeigen und so die Fehlersuche vereinfachen sowie unnötige Ticketerstellung verhindern.
- Läuft ein GeNiJack, Agent oder Server mal nicht rund, kann dieser einfach in das Monitoring aufgenommen werden und das Problem somit näher eingegrenzt werden.
Welche Möglichkeiten haben wir in GeNiEnd2End, um Performance / Service-Metriken abzurufen?
Alle GeNiJacks verfügen über die Möglichkeit, Systemperformance und Service-Metriken per SNMP zur Verfügung zu stellen.
Ab Version 6.2.XXX werden auch die Zustände des GeNiAgenten und der anderen Services über SNMP ausgegeben. In älteren Versionen bedarf es manueller Anpassung einer Datei, damit auch dort die Daten gesammelt werden können. Es ist empfehlenswert, die GeNiJacks auf die aktuellste Version anzuheben. Bei weiteren Fragen dazu melden Sie sich bitte bei uns: support@netcor.de.
Alle GeNiAgenten auf einem Windows Betriebssystem können über WMI abgefragt werden - so wie bei jedem anderen Windows-Gerät auch. Um WMI zu aktivieren, kontaktieren Sie bitte Ihren Administrator. Hier gibt es oft Firmenvorgaben, ob und wie das geschieht.
Der GeNiEnd2End Server kann über WMI abgefragt werden und es gibt die Möglichkeiten, jede Form von Daten, die in den Datenbanken enthalten sind, über die REST API abzufragen. Diese gibt die angeforderten Daten als JSON (z.B. für Messwerte, Agenten Informationen) aus.
Was ist sinnvoll zu überwachen?
Der GeNiServer verwaltet und überwacht die Agenten bereits und generiert Alarme, liefert aber keine historischen Übersichten. Der Status der GeNiAgent Prozesse, die Erreichbarkeit und die Festplattenbelegung werden überwacht. Wenn Sie ein Problem mit einem GeNiAgenten oder GeNiJack haben, empfiehlt es sich, diesen genauer zu überwachen und/oder die Alarm-Benachrichtigung im GeNiServer entsprechend anzupassen.
| GeNiAgent und GeNiJack | GeNiServer |
Sinvoll
|
Sinnvoll
|
Möglich
|
Möglich
|
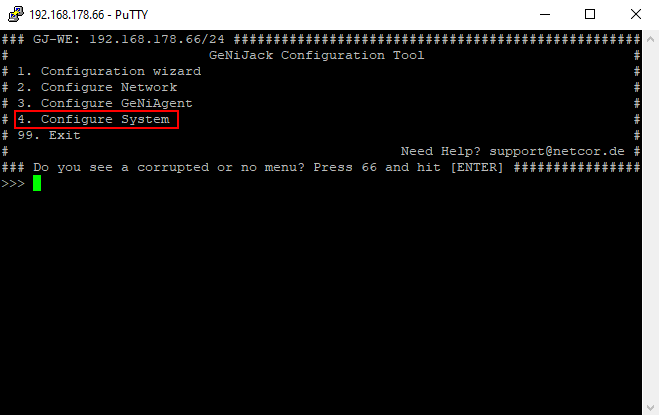
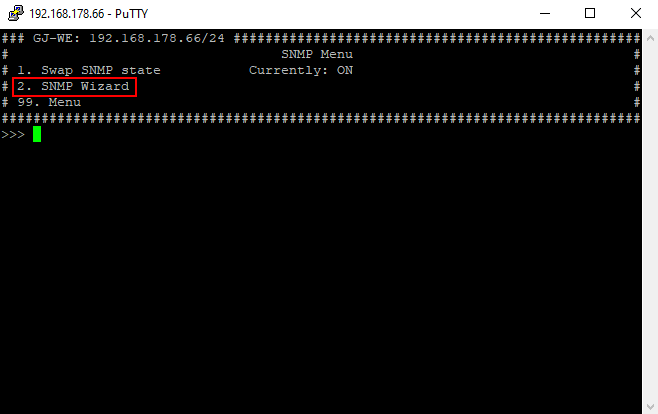
Wir aktiviere ich SNMP auf einem GeNiJack?
SNMP wird über SSH im GeNiJack Manager aktiviert und konfiguriert.
- Herstellen einer SSH-Verbindung zu einem GeNiJack und anmelden mit dem admin Benutzer.
- Im GeNiJack Manager Menüpunkt "4" auswählen, anschließened Menüpunkt "5".
- Jetzt den SNMP-Wizard durchlaufen, Menüpunkt "2" der die benötigten Daten für den SNMP-Dienst hinterlegt (z.B. Read/Write Community, Location usw.)
- Aktivieren des SNMP-Dienstes mit dem Menüpunkte "1".
- Jetzt das SNMP-Menü mit "99" verlassen mit und einen Reboot mit dem Menüpunkt "12" auslösen.
 |
 |
 |
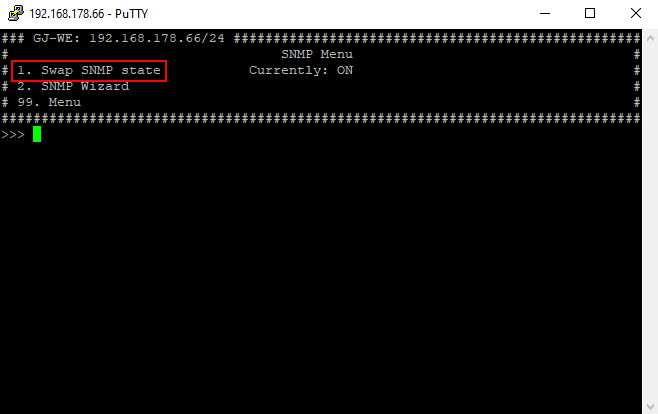 |
| System configuration | SNMP settings | SNMP Wizard | Swap SNMP state |
Jetzt können Sie mit der von Ihnen konfigurierten Read Community die Performance / Service-Metriken des GeNiJacks in Ihrem Monitoring Tool abfragen.
Wie kann ich die Performance / Service Metriken abfragen?
Wir zeigen nun an einem Beispiel von Paessler PRTG, wie man die Metriken abfragt und ein Dashboard erstellt.
Bevor Sie mit der Abfrage aller Geräte Ihrer GeNiEnd2End-Umgebung anfangen, sollten Sie sich überlegen, wo in Ihrem Gerätebaum und in welcher Struktur die Geräte integriert werden sollen. Wenn Sie eine einfache Übersicht über den Status aller Agenten und GeNiJacks haben wollen, empfiehlt es sich zwei getrennte Gruppen zu erstellen.
Abfragen aller Metriken der GeNiEnd2End-Umgebung:
- GeNiJacks / GeNiAgenten / GeNiServer in PRTG mit den passenden Sensoren (SNMP, WMI) hinzufügen.
- Um den Status von GeNiEnd2End-Prozessen auf den GeNiJacks anzuzeigen, ist ein spezieller SNMP-Sensor in PRTG notwendig.
- Den Sensor installieren: "Custom UCD-SNMP Linux Process v0.2"
 Paessler Knowledgebase.
Paessler Knowledgebase. - SNMP muss nach der obigen Anleitung auf den GeNiJacks aktiviert und Version 6.2.XXX oder höher installiert sein.
- Bei allen GeNiJacks per Rechtsklick eine "Automatische Suche mit Vorlage ausführen" mit dem angegebenen Sensor.
- Sollten die Prozesse nicht erkannt werden überprüfen Sie, ob der GeNiJack auch auf der aktuellsten Version ist.
- Den Sensor installieren: "Custom UCD-SNMP Linux Process v0.2"
- Abfragen von Werten vom GeNiServer aus der Datenbank.
- Konfiguration der Poll-Intervalle für die Geräte.
Wie kann ich eine Übersicht über den Status/Performance der GeNiEnd2End Umgebung bekommen?
Das hängt natürlich immer von den Möglichkeiten des eingesetzten Monitoringsystems ab - diese sollten evaluiert werden.
Bei den meisten Monitoringsystemen gibt es eine Art von Dashboards, in PRTG werden diese auch Maps genannt. Dashboards liefern oft ein breites Spektrum von Anzeigemöglichkeiten, von Ampeln bis hin zu Charts und Tachos.
Wenn die GeNiServer REST API abgefragt werden soll, muss das Monitoringsystem mit der umfangreichen JSON-Rückgabe zurechtkommen. Es wird von der API immer der komplette Eintrag zu dem Test / Agenten, usw. zurückgeliefert.
Erstellen eines Dashboards:
Um einen Überblick zu bekommen, wie man eine Map in PRTG erstellt und welche Möglichkeiten es gibt, empfiehlt es sich folgende Informationen anzuschauen und dann mit unserem Guide fortzufahren.
PRTG Tutorial - How to Set Up a Map
PRTG Tutorial - How to use maps
Nachdem alle gewünschten Geräte hinzugefügt wurden und die Messwerte gesammelt werden, kann nun mit dem Erstellen des Dashboards begonnen werden. Wie in den verlinkten Videos von Paessler zu sehen ist, ist das eigentliche Erstellen einfach - vor allem wenn man sich ungefähr vorstellen kann, was dabei ersichtlich werden soll.
Ein Dashboard ist umso besser, desto einfacher und schneller man mögliche Fehler erkennt. Hierbei sollte man auch nach Detailgrad unterscheiden. Eine "einfache" Übersicht, die ausschließlich alle Agenten / GeNiJacks / Infos zum GeNiEnd2End Server und den Status der Tests anzeigt, ergibt für die schnelle Erkennung, ob ein Fehler wie im folgenden Beispiel vorliegt, besonders viel Sinn.
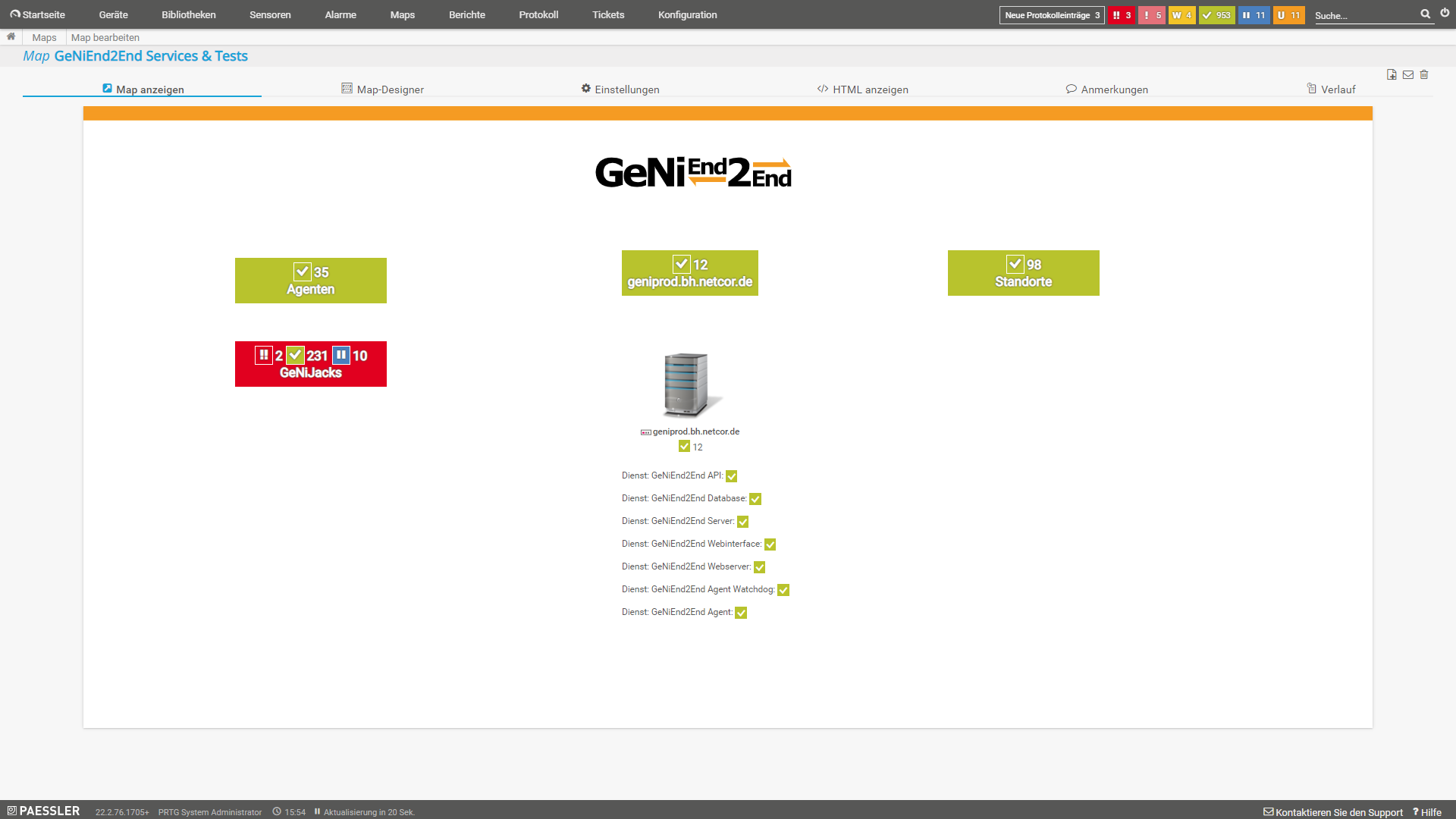 |
| Dashboard - GeNi Services |
Hier wurde für die meisten Anzeigen das Map Element "Name und Status (größenveränderlich, zustandsabhängiger Hintergrund)" genutzt und dann die entsprechenden Gruppen Agenten / GeNiJacks / GeNiServer sowie Standorte als Datenquelle genutzt. Damit ist schnell ersichtlich, sobald ein Element rot wird, ob und wo es ein Problem gibt.
Die Anzeigen der GeNiServer Services sind das Element "Name und Status (Standardhintergrund)", dort werden ausschließlich die Windows Dienste des GeNiServers als Datenquelle genutzt. Das Dashboard ist simpel und zeigt in dem Beispiel direkt einen Fehler bei den GeNiJacks an. Über ein Drill Down kann man zu dem Problem vordringen, das auf den GeNiJacks vorliegt. Wenn Sie möchten ist es auch möglich, eine "Alarmliste" auf dem Dashboard zu platzieren. Solch ein Widget sehen Sie auf dem Dashboard - Große Umgebung (simpel).
Allerdings können auch andere Darstellungen einen Mehrwert liefern, gerade wenn es um eine Übersicht von mehreren Standorten geht.
Hier gibt es ein paar Beispiele für verschiedene GeNiEnd2End Dashboards aus unserer PRTG Demo-Umgebung:
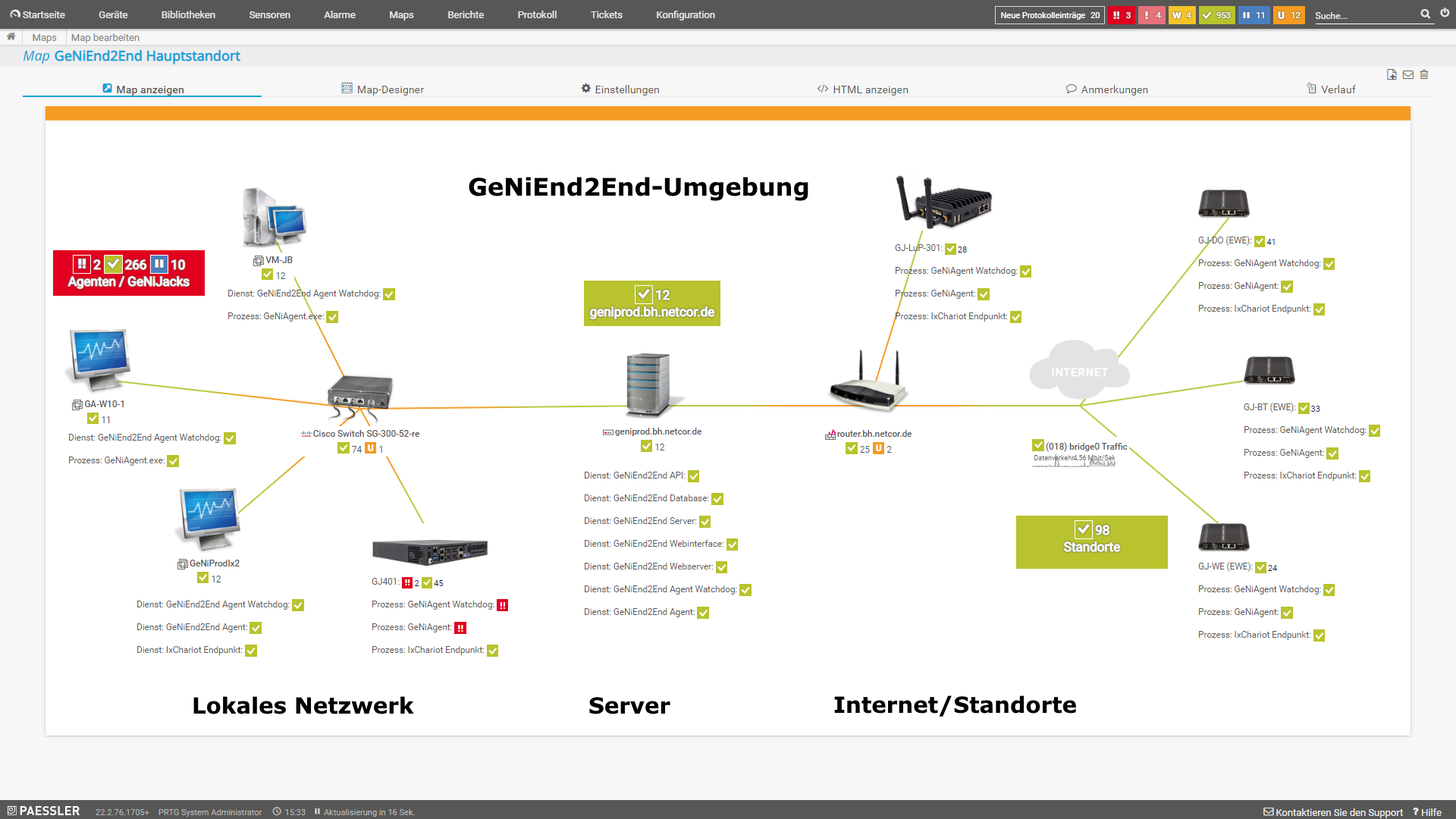 |
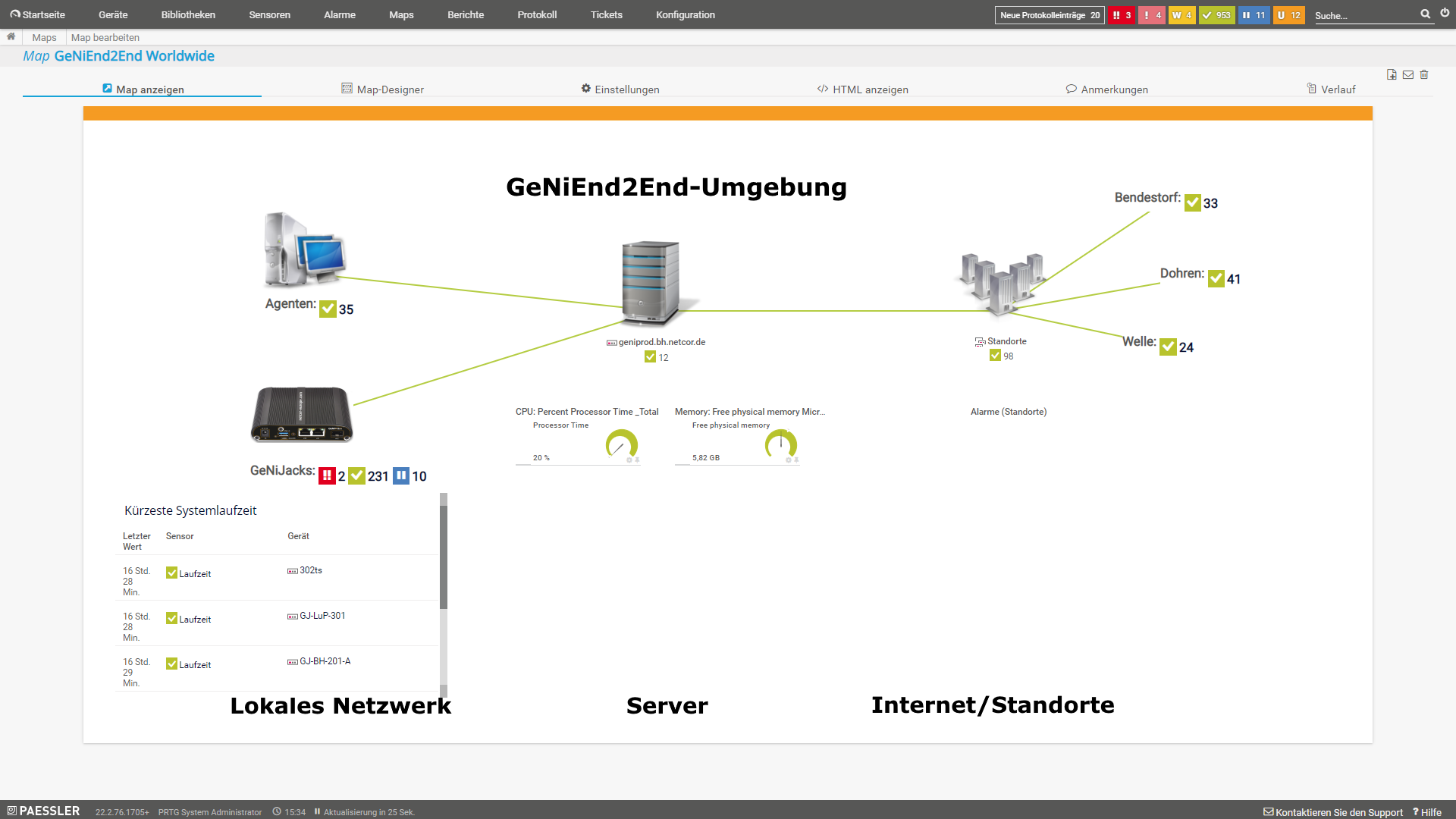 |
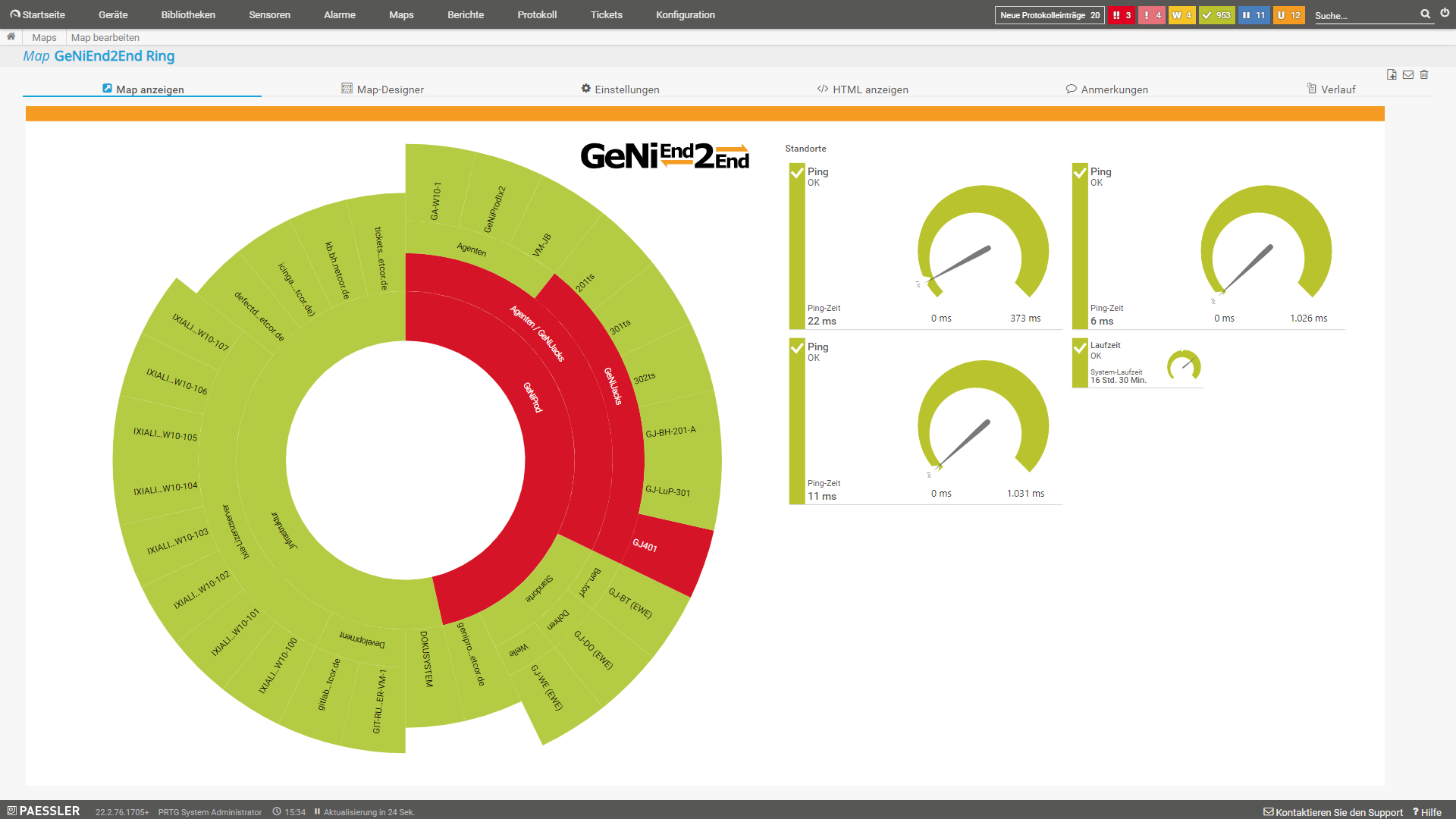 |
| Dashboard - Kleine Umgebung (ausführlich) | Dashboard - Große Umgebung (simpel) | Dashboard - Ring Darstellung |
Bei Fragen oder für weitere Informationen, melden Sie sich einfach bei uns.
Als Auswirkung von kurzzeitiger Überlast in Netzwerken, z.B. an Übergängen ins WAN, treten häufig Microbursts auf, die die Performance von Anwendungen merklich verschlechtern.
Leider werden diese Microbursts von den gängigen SNMP-Monitoring Lösungen aufgrund ihrer „groben Messauflösung“ nicht erfasst und stellen so die IT-Verantwortlichen vor eine große Herausforderung, die Ursache zu ermitteln.
Wir erklären Ihnen die Auslöser und Auswirkungen von Microbursts und zeigen Ihnen, wie Sie diese mit ![]() Wireshark oder noch effizienter mit dem
Wireshark oder noch effizienter mit dem ![]() Allegro Network Multimeter analysieren können.
Allegro Network Multimeter analysieren können.
Als jemand, der Netzwerke plant, betreut und optimiert, haben vermutlich auch Sie häufiger die Herausforderung, dass Sie bei schlechter Applikationsperformance Probleme lösen sollen, die Sie eventuell gar nicht zu verantworten haben.
Durch die vermehrte Nutzung von SaaS und Cloud-Applikationen ist eine Fehlerzuordnung bzw. die Fehleranalyse noch deutlich schwieriger geworden: Herkömmliche Network Performance Monitoring Lösungen sind für private Netzwerkinfrastrukturen konzipiert. Ihre Architektur und Fähigkeiten sind nicht für Cloud-Umgebungen geschaffen, es gibt zwangsläufig Blind Spots.
In diesem Video zeigen wir Ihnen, wie Sie mit Hilfe der ![]() Kadiska Digital Experience Monitoring Platform Performanceprobleme von Cloud-Applikation (zum Beispiel Office 365, SAP und webbased Applikationen) analysieren können.
Kadiska Digital Experience Monitoring Platform Performanceprobleme von Cloud-Applikation (zum Beispiel Office 365, SAP und webbased Applikationen) analysieren können.
Als am 10. Dezember 2021 eine Zero-Day-Lücke in Log4j-Version 2 bekannt wurde, schrillten in zahlreichen Unternehmen die Alarmglocken.
Täglich werden Schwachstellen in Software gefunden, geschlossen und auch ausgenutzt. Der Unterschied zu den meisten vorherigen Sicherheitslücken lag darin begründet, dass nicht sofort erkennbar war, welche Software überhaupt Log4j beinhaltet und dadurch betroffen ist.
Immer öfter entsteht Software durch Zusammenfügen von mehreren fertigen und funktional ausgezeichneten Komponenten oder durch die Nutzung von fertigen Frameworks, die wiederum auch Abhängigkeiten von ihren Komponenten mitbringen. Ob benötigte Komponenten oder unnötiger Ballast: Die Nutzung von SBOM ist in der Theorie nach wie vor entschieden häufiger anzutreffen als in der Realität.
Und so standen dann im Dezember 2021 viele IT-Sicherheitsverantwortliche vor der Herausforderung, möglichst schnell beantworten zu können, an welchen Stellen Gefahr bestand.
Eine Möglichkeit, zügig und umfassend herauszufinden, wo Log4j in der benutzten Softwarelandschaft verwendet wird, bietet die ![]() Axonius Cybersecurity Asset Platform.
Axonius Cybersecurity Asset Platform.
Auch wenn Log4j mittlerweile kalter Kaffee ist - eine nächste Sicherheitslücke an einer zentralen Komponente wird es geben. Wie Sie diese in Ihrer IT lokalisieren, erfahren Sie in diesem Video.
In dieser Aufzeichnung stellen wir Ihnen die Neuerungen der Version 6.2 von GeNiEnd2End vor.
Dies sind einige der Verbesserungen:
- Neuer iPerf3 Application Light Test
- Neuer Application FirstAid Test
- Neuer Network Test Wizard
- LLDP-Unterstützung
- Umstellung der genutzten Python-Version auf 3.X (Server, Agents, GeNiJacks, Scripte)
- Python-Version angepasst auf 3.x
- GeNiJack Debian-Version 10.10
Sollten Sie dazu Fragen haben oder Unterstützung bei dem Update benötigen, melden Sie sich gerne bei uns:
+49 4181 9092-110
support@netcor.de
Immer komplexer werdende IT-Infrastrukturen, ohne die die für den Unternehmenserfolg erforderlichen Prozesse gar nicht umsetzbar wären, erfordern neben ausgeprägtem Fachwissen auch hilfreiche Werkzeuge.
Diese sollen die IT-Verantwortlichen dabei unterstützen, einen reibungslosen Betrieb sicherzustellen und in einem eventuellen Fehlerfall die Ursache schnell zu erkennen und zu beheben.
Um auftretende Probleme unmittelbar erkennen oder gar vermeiden zu können, wird ein intelligentes 24x7 Monitoring der für den IT-Betrieb wichtigen Komponenten sowie der Verbindungspfade unverzichtbar.
Wir zeigen Ihnen, wie Sie Ihre Netzwerkinfrastruktur effizient mit ![]() Paessler PRTG überwachen können.
Paessler PRTG überwachen können.
In einer Live-Demo erfahren Sie, wie eine schnelle Fehlerlokalisierung mittels einer Ende-zu-Ende Pfadanalyse bei einem Performanceproblem eines Webservers aussieht.
Ein weiterer Punkt ist die automatische Erstellung eines Netzwerkplans mit ![]() IP Fabric und wie Inkonsistenzen sowie Probleme beim BGP-Peering, die die Netzstabilität beeinflussen, automatisch identifiziert werden können.
IP Fabric und wie Inkonsistenzen sowie Probleme beim BGP-Peering, die die Netzstabilität beeinflussen, automatisch identifiziert werden können.
18.06.2021
Dabei gehen wir auch darauf ein, wie eine intelligente Alarmierung proaktiv Fehler erkennt und den Workflow im Fehlerfall effizienter gestaltet. Ein weiterer Punkt ist die zielgenaue Analyse von Microbursts, Retransmission und Laufzeit mit
Wir verraten Ihnen auch, wie Sie verschlüsselten Datenverkehr analysieren können.
Seit SaaS- und Cloud-Dienste salonfähig geworden sind, hat sich in der IT viel geändert. Trotz der vielen Vorzüge der Auslagerungen der IT-Services, gibt es neue Herausforderungen beim Nachverfolgen der Verfügbarkeit und Performance dieser Dienste.
Es gibt neue Unsicherheitsfaktoren auf dem Netzwerkpfad von den Benutzern zur Cloud-Plattform. Das Maß an Kontrolle, das die IT-Abteilung darauf hat, ist im Vergleich zu den herkömmlichen Netzwerkinfrastrukturen gesunken.

Folgende neue Begleiterscheinungen beim Outsourcing in die Cloud können die User-Experience unkontrollierbar negativ beeinflussen:
- Die lokale Netzwerkkonnektivität im Home-Office
- Das Peering- und Transitverhalten
- Der Weg zum Sicherheitsgateway
- Die Auswirkungen der Optimierungen von BGP-Richtlinien und Routing-Tabellen
- Die Auswahl der CDN-Strategie und SaaS-Anbieter
- Die geographischen Ressourcen des Cloud-Anbieters
Durch diese Entwicklung ist es sinnvoll, die Service-User-Sicht, beziehungsweise den Netzwerkpfad vom Anwender zum Cloud-Anbieter, stärker ins Monitoring aufzunehmen.
Zum Glück gibt es Anbieter von Monitoringlösungen, die diesen Wandel erkannt haben und eine neue Sichtweise auf die globale User-Experience in den Vordergrund stellen.
Eine solche Sicht liefert zum Beispiel die ![]() Kadiska Digital Experience Monitoring Platform von Kadiska. Durch eine Kombination von synthetischen Tests und passives End-to-End-Monitoring können schnell Serviceverschlechterungen, deren Umfang und Ursache erkannt werden. Unverzichtbar für eine effiziente Problembehebung.
Kadiska Digital Experience Monitoring Platform von Kadiska. Durch eine Kombination von synthetischen Tests und passives End-to-End-Monitoring können schnell Serviceverschlechterungen, deren Umfang und Ursache erkannt werden. Unverzichtbar für eine effiziente Problembehebung.
Bei Interesse stellen wir Ihnen Kadiska gerne vor - oder fordern Sie eine ![]() Teststellung an.
Teststellung an.
Wenn Anwender Schwierigkeiten bei der Nutzung wichtiger Applikationen haben, ist es insbesondere an Standorten ohne lokale Netzwerkspezialisten nicht einfach, Daten für eine Paketanalyse zu erhalten.
Wir zeigen Ihnen, wie Sie mit dem ![]() EtherScope nXG nah am Anwender Troubleshooting betreiben können - ohne selbst vor Ort sein zu müssen. Alle erforderlichen Daten werden automatisch erfasst und einem Spezialisten für eine Paketanalyse zur Verfügung gestellt.
EtherScope nXG nah am Anwender Troubleshooting betreiben können - ohne selbst vor Ort sein zu müssen. Alle erforderlichen Daten werden automatisch erfasst und einem Spezialisten für eine Paketanalyse zur Verfügung gestellt.
Der kann sich dann mit ![]() Wireshark auf die Fehlersuche begeben.
Wireshark auf die Fehlersuche begeben.
Klagen Anwender über schlechte Antwortzeiten Ihrer Anwendungen, heißt es typischerweise „das Netzwerk ist heute wieder langsam"! Schnell ist der Netzwerkverantwortliche in der Pflicht.
Er muss nachweisen, ob die gemeldeten Probleme durch die Netzwerkinfrastruktur verursacht werden oder nicht. Als Hilfsmittel wird dabei gern auf Lösungen wie zum Beispiel iPerf zurückgegriffen.
Wir erläutern Ihnen Einsatzszenarien für Ende-zu-Ende-Messungen und zeigen Ihnen Stärken und Schwächen von iPerf. Mit ![]() IxChariot stellen wir Ihnen ein Tool vor, dass einen sehr ähnlichen Ansatz wie iPerf hat, jedoch deutlich mehr Möglichkeiten bietet.
IxChariot stellen wir Ihnen ein Tool vor, dass einen sehr ähnlichen Ansatz wie iPerf hat, jedoch deutlich mehr Möglichkeiten bietet.
Im Zusammenspiel mit ![]() GeNiEnd2End erhalten iPerf und
GeNiEnd2End erhalten iPerf und ![]() IxChariot eine benutzerfreundliche Oberfläche, 24/7-Tests und reale QoS Test. Die Messergebnisse können dabei zur Reporterstellung genutzt werden - auch für externe Leistungserbringer und Provider.
IxChariot eine benutzerfreundliche Oberfläche, 24/7-Tests und reale QoS Test. Die Messergebnisse können dabei zur Reporterstellung genutzt werden - auch für externe Leistungserbringer und Provider.
28.04.2021
Wenn Anwender über schlechte Anwendungsperformance klagen, wird das Problem meist an den Netzwerkverantwortlichen weiter gegeben, um die Ursache dafür herauszufinden. Als Performancekiller können sich dabei Probleme mit TCP Window oder Application Blocksize herausstellen, die nicht auf die verfügbare Bandbreite optimiert wurden.
Wir beschäftigen uns in diesem Webinar mit den Grundlagen von Window Size und Application Blocksize. Zusätzlich zeigen wir Ihnen, wie Sie Retransmissions mit ![]() Wireshark analysieren und was verpasste TCP-Daten, Dup Ack und Retransmissions überhaupt in Theorie und Praxis bedeuten.
Wireshark analysieren und was verpasste TCP-Daten, Dup Ack und Retransmissions überhaupt in Theorie und Praxis bedeuten.
Da leider selbst Wireshark nicht für alle Aufgaben optimal ist, werfen wir einen Blick auf das ![]() Allegro Network Multimeter, das insbesondere bei Langzeitstatistiken und generell bei großen Capture-Files seine Stärken zeigen kann.
Allegro Network Multimeter, das insbesondere bei Langzeitstatistiken und generell bei großen Capture-Files seine Stärken zeigen kann.
07.04.2021
Selbst ein zuverlässig geplantes und funktionierendes WLAN kommt eines Tages an seine Grenzen. Mit der Zeit verändern sich die Anforderungen an das WLAN durch technische Notwendigkeiten, weitere Prozesse benötigen drahtlosen Netzzugriff und die Erwartungen von Nutzern verändern sich ebenfalls.
Steht eine Modernisierung des WLANs an, stellt sich die Frage, ob man einfach 1:1 Access Points ersetzt oder ob es sinnvoller ist, anhand der gewachsenen Anforderungen, neuer WLAN-Standards und besserer Funkleistungen das WLAN vollständig neu zu planen.
Wie Sie eine WLAN-Modernisierung effizient mit ![]() Ekahau designen & validieren können, zeigen wir Ihnen in diesem Webinar.
Ekahau designen & validieren können, zeigen wir Ihnen in diesem Webinar.
Angetrieben von dem Wunsch der Effizienzsteigerung und der Hoffnung auf mehr Flexibilität werden nach wie vor Rechenzentren ausgelagert und Ressourcen zentralisiert.
Dadurch, dass Datenpakete dann einen anderen Weg als zuvor zurücklegen müssen, kann es zu Performanceproblemen kommen.
Gleichzeitig steigt nach einer Auslagerung auch die Komplexität bei der Erkennung und Analyse von eventuell auftretenden Performanceproblemen deutlich an.
Wir stellen Ihnen wichtige Parameter sowie Lösungsansätze vor, die Ihnen helfen, die Ursache/n für schlechte Performance effizient zu erkennen und zu beseitigen.
Für den praktischen Teile verwenden wir ![]() Riverbed SteelCentral AppResponse.
Riverbed SteelCentral AppResponse.
Nach wir vor sind deutlich mehr Mitarbeiter als in der Vergangenheit im Homeoffice. Für die Zusammenarbeit wird dabei auf Tools wie zum Beispiel GoToMeeting, Teams, WebEx und Zoom gesetzt.
Wie bei jeder anderen Applikation kann es auch hier zu Performanceproblemen kommen. Sie erfahren, wo die Herausforderungen bei der Analyse der Qualitätsprobleme liegen und mit welchen Messverfahren Sie bei Verwendung von TCP und UDP(IPSEC)/RTP herausfinden können, wo das Problem verursacht wird.
In der Live-Demo zeigen wir Ihnen mit realen Daten den Workflow der verwendeten Lösungen ![]() Allegro Network Multimeter und
Allegro Network Multimeter und ![]() NETCOR GeNiEnd2End.
NETCOR GeNiEnd2End.
Den erwähnten Artikel aus der LANline können Sie hier lesen:
![]() Blinde Flecken beim SNMP-Monitoring - Die Last mit der Last
Blinde Flecken beim SNMP-Monitoring - Die Last mit der Last
Häufige Änderungen an den Routing-Konfigurationen sind ein Anzeichen von der Instabilität des Peerings und können zu Netzstörungen oder sogar Ausfällen führen. Die klassischen SNMP-Monitoringtools sind meistens nicht in der Lage, diese Probleme zu erkennen.
Um Störungen in der Netzwerkredundanz frühzeitig erkennen zu können, empfiehlt es sich, die Betriebszustände der Netzwerkknoten kontinuierlich zu überwachen.
Mittlerweile gibt es Managementsysteme, die diesen Administrationsprozess automatisieren und Probleme - verursacht durch Änderungen in den Peering-Beziehungen - ohne Expertenwissen frühzeitig erkennen.
Im Video zeigen wir Ihnen, wie die ![]() Netzwerkinfrastruktur-Management-Plattform vom Hersteller IP Fabric Ursachen von BGP-Instabilität automatisch aufzeigen kann und nebenbei sogar eine aktuelle Netzwerkdokumentation liefert.
Netzwerkinfrastruktur-Management-Plattform vom Hersteller IP Fabric Ursachen von BGP-Instabilität automatisch aufzeigen kann und nebenbei sogar eine aktuelle Netzwerkdokumentation liefert.
Auch wenn wir mit dem neuen ![]() GeNiJack 302 keinen Hype wie bei iPhone & Co. auslösen werden, wird dieser GeNiJack den Netzwerker nicht eiskalt lassen.
GeNiJack 302 keinen Hype wie bei iPhone & Co. auslösen werden, wird dieser GeNiJack den Netzwerker nicht eiskalt lassen.

NETCOR GeNiJack 302 kann auch über WLAN messen
Einige Kunden planen den GeNiJack 302 zur Überwachung der Funknetze aus Anwendersicht in Meetingräumen einzusetzen. Somit kann der Netzwerker die End-User-Experience objektiver bewerten, was ihm eine effizientere Fehleranalyse bei Performanceproblemen ermöglicht.
Um die Übersicht über Ihr Netzwerk zu behalten, setzen unsere Kunden gerne das ![]() Network Multimeter von Allegro Packets als Ergänzung zu Wireshark ein. Die Benutzeroberfläche ist intuitiv zu bedienen, aber um es produktiv einsetzen zu können, ist es wichtig, die Zusammenhänge zwischen den gelieferten Messwerten des Network Multimeters herstellen zu können.
Network Multimeter von Allegro Packets als Ergänzung zu Wireshark ein. Die Benutzeroberfläche ist intuitiv zu bedienen, aber um es produktiv einsetzen zu können, ist es wichtig, die Zusammenhänge zwischen den gelieferten Messwerten des Network Multimeters herstellen zu können.

Allegro Network Multimeter
Ähnlich wie beim Förster, der weiß, was die einzelnen Bäume miteinander verbindet, sollte der Netzwerker das Wissen beherrschen, die Vielzahl der Echtzeit-Netzwerkstatistiken des Network Multimeters für die Fehleranalyse miteinander verbinden zu können.
Hierfür haben wir die praxisnahe ![]() Allegro Packets Schulung entwickelt. Entweder als Inhouse-Schulung oder auch als Webmeeting können unsere erfahrenen Consultants individuell auf die Teilnehmer und deren Vorkenntnisse eingehen. Gerne wird diese Schulung auch mit unserer Wireshark-Schulung kombiniert.
Allegro Packets Schulung entwickelt. Entweder als Inhouse-Schulung oder auch als Webmeeting können unsere erfahrenen Consultants individuell auf die Teilnehmer und deren Vorkenntnisse eingehen. Gerne wird diese Schulung auch mit unserer Wireshark-Schulung kombiniert.
Also bevor Sie bei einem Netzwerkproblem den Wald vor lauter Bäumen nicht mehr erkennen und Sie die Kettensäge auspacken, buchen Sie besser unsere ![]() Netzwerkanalyseschulungen.
Netzwerkanalyseschulungen.
Schenken und beschenkt werden - beides bereitet Freude. Wir haben uns diese Woche ganz besonders darüber gefreut, wie uns ein Kunde sein Vertrauen geschenkt hat.
Bestellt hat er bei uns gleich 70 Exemplare vom ![]() GeNiJack 301. Auch wenn es der Regelfall ist, dass mehrere GeNiJacks eingesetzt werden, ist das schon eine überdurchschnittliche Größenordnung.
GeNiJack 301. Auch wenn es der Regelfall ist, dass mehrere GeNiJacks eingesetzt werden, ist das schon eine überdurchschnittliche Größenordnung.

70 GeNiJack 301 auf einen Streich
Da GeNiJacks bislang typischerweise nicht mal bei uns unter dem Weihnachtsbaum liegen, bleibt die Frage nach dem Ansinnen von unserem Kunden.
GeNiJack 301 verfügt über eine starke Quadcore CPU und kann so auch über einen längeren Zeitraum duplex voll ausgelastete Gigabit-Verbindungen messen.
In diesem Projekt wird der Kunde die GeNiJacks weltweit ausrollen und damit sein SDN monitoren. Sollte sich durch eine Konfigurationsänderung im SDN die Ende-zu-Ende-Performance verändern, bekommt der Kunde dies umgehend mit und kann so stets eine hohe Servicequalität ermöglichen.
Sollte es hartnäckige Netzwerkprobleme geben, kann die integrierte 500GB Festplatte für Packet Capturing genutzt werden. Die Daten können dann für Detailanalysen an ![]() Wireshark weitergereicht werden.
Wireshark weitergereicht werden.
Durch die Episoden führt Sie ein Kollege, der seit mehr als 10 Jahren Anwender im sicheren Umgang mit Wireshark schult.
Teil 1: Einführung in Wireshark
Teil 2: Strategien und effizienter Einsatz von Wireshark
Teil 3: Mit Wireshark gemessene Daten visualisieren
Ekahau hat am 09.04.2019 Neuigkeiten zu Ekahau Site Survey bekanntgegeben.
Ekahau Site Survey heißt jetzt ![]() Ekahau Pro und es gibt keine Standard-Version mehr.
Ekahau Pro und es gibt keine Standard-Version mehr.
Es wurde ![]() Ekahau Pro 10 mit folgenden Verbesserungen freigegeben:
Ekahau Pro 10 mit folgenden Verbesserungen freigegeben:
- Überarbeitetes und deutlich schnelleres Benutzerinterface
- 802.11ax Unterstützung (APs, Erkennung und passive Messungen)
- Erkennen und Klassifizieren von Interferenzen
- Verbesserte AP Liste
- Verbesserte AP Lokalisierung
- Bei dem Sidekick wurde der integrierte Speicher freigeschaltet (128GB)
Kunden mit einem aktiven Supportvertrag können die Version hier herunterladen: ![]() Ekahau Download
Ekahau Download
Dazu kommt noch ein neues Supportprogramm, genannt ![]() Ekahau Connect, was vor allem für Nutzer mit
Ekahau Connect, was vor allem für Nutzer mit ![]() Ekahau Sidekick gedacht ist.
Ekahau Sidekick gedacht ist.
Dieses Supportprogramm bietet einige sehr interessante Vorteile, die Sie ab sofort erhalten können.
Ekahau Connect beinhaltet:
- Ekahau Survey for iPad
- Ekahau Capture
- Ekahau Cloud
- Ekahau Connect Training
Weitere Infos dazu finden Sie auf der ![]() Ekahau Connect Produktseite.
Ekahau Connect Produktseite.
Durch die umfassenden Änderungen haben sich die Preise geändert und es gibt neue Artikelnummern.
Bei Fragen oder für weitere Informationen, melden Sie sich einfach bei uns.
Ekahau hat ein sehr informatives Webmeeting (Englisch) zum Thema WLAN-Interferenzen gehalten, was über Youtube angeschaut werden kann.
Es behandelt unter anderem folgende Themen:
- Was sind Interferenzen?
- Typen von Interferenzen
- Typische Quellen von Interferenzen
- Wie beeinflussen Interferenzen die WLAN-Verbindung - mit Beispielen

Von Uila AA-IPM unterstützte Cloud Anbieter
Die Übersicht der Serviceabhängigkeiten kann auch aufzeigen, welche VM- \ Service-Probleme durch eine andere VM entstehen, wenn z.B. der Webserver die Datenbank einer anderen VM abfragt und dadurch die Antwortzeiten des Webservers "langsam" sind. Hier hilft auch die Root Cause Analyse Funktion, um den eigentlichen Verursacher auf den Zahn zu fühlen.
Interesse an ![]() Uila AA-IPM? Sie können es in unserem
Uila AA-IPM? Sie können es in unserem ![]() NETCOR Performance Check 30 Tage kostenlos testen.
NETCOR Performance Check 30 Tage kostenlos testen.
20.02.2018
Wenn Geschäftsapplikationen immer wieder haken und das System Monitoring durch die Flut an nicht korrelierten Performancedaten den gewünschten Rückschluss auf den/die Verursacher nicht darstellen kann, bleiben die Performanceprobleme im Dunkeln.
|
Bei den klassischen Management-Tools in virtualisierten Rechenzentren werden grundlegende Performancedaten wie CPU-, Speicher-, Storage und Netzwerkauslastung gesammelt, allerdings liefern diese Kennzahlen erstmal eine quantitative Aussage zu der Performance. Sie liefern aber keinen Rückschluss zu den Applikationsantwortzeiten. Diese Überwachungslücke wird mit der |
 |
Die ![]() Uila AA-IPM Software ist eine schnell zu implementierende und bezahlbare Lösung für eine anwendungsorientierte Überwachung von der Private- und Hybrid-Cloud.
Uila AA-IPM Software ist eine schnell zu implementierende und bezahlbare Lösung für eine anwendungsorientierte Überwachung von der Private- und Hybrid-Cloud.
Für den AirCheck G2 ist eine Neue Firmware Version erschienen die bei aktivem Gold Support einfach heruntergeladen und installiert werden kann.
Diese beinhaltet einige wichtige Features, die schon lange auf der Wunschliste standen:
iPerf Testing:
Endlich ist es möglich, direkt mit dem AirCheck G2 iPerf Tests (TCP/UDP) gegen einen iPerf Server durchzuführen.
Captive Portals:
Es ist jetzt möglich, WLAN-Verbindungen zu überprüfen die mit einem Captive Portal gesichert sind. Es ist auf dem Gerät im Profil für die WLAN-Netzwerke hinterlegbar.
Interferer Detection - Störererkennung:
Der AirCheck G2 zeigt nun auch Störer im 2.4 GHz und 5 GHz Bereich an. Das ist enorm hilfreich, um Geräte zu erkennen und aufzuspüren, die das WLAN stören aber selber nicht per WLAN kommunizieren. Hierunter fallen viele Geräte wie drahtlose Telefone, drahtlose Videokameras, Bewegungsmelder usw. Um solche Störer aufzuzeigen war es vorher immer nötig, den ![]() AirMagnet Spectrum XT gleich dabei zu haben. Jetzt kann erstmal geschaut werden, ob es Probleme gibt und dann werden sie mit dem
AirMagnet Spectrum XT gleich dabei zu haben. Jetzt kann erstmal geschaut werden, ob es Probleme gibt und dann werden sie mit dem ![]() AirMagnet Spectrum XT weiter eingegrenzt.
AirMagnet Spectrum XT weiter eingegrenzt.
Autorisationsklassifizierung:
Es ist nun möglich, WLAN-Geräte zum Beispiel danach zu klassifizieren, ob diese zu dem Unternehmen gehören oder ein Gerät eines Nachbars sind oder ein unbekanntes Gerät (Rogue).
Hier gibt es den Download der neuen Version : ![]() AirCheck G2 Gold Support benötigt
AirCheck G2 Gold Support benötigt
Hinweis: Für den Download der Firmware V2 benötigen Sie einen aktiven Gold Support für den AirCheck G2. Sollte Ihnen dieser noch fehlen, können Sie sich gerne für ein Angebot bei uns melden.
Ein Video das die neuen Funktionen zeigt gibt es hier (Englisch):
Es gibt Problemfälle, in denen die Informationsdichte auf Basis der Datenpakete für die Fehleranalyse im ersten Schritt zu detailliert ist. Ohne konkrete Anhaltspunkte ist eine Analyse von Terabyte großen Tracefiles - in denen lediglich eventuell der Fehler steckt - nicht zielführend. Es fehlt der Überblick, auch gerade in Hinblick auf die Zeitdimension.
Um mehr Überblick zu bekommen, empfehlen wir unseren Kunden das ![]() Network Multimeter von Allegro Packets. Es handelt sich hier um eine mobile Problemdiagnose-Lösung in unterschiedlichen Systemgrößen, geeignet für den Einsatz in 1G/10G/40G und 100G Netzen. Die intuitive und webbasierende Benutzeroberfläche liefert sowohl eine Echtzeit- als auch eine rückwirkende Sicht auf den Netzwerkverkehr und unterstützt einen strukturierten Workflow bei der Problemdiagnose.
Network Multimeter von Allegro Packets. Es handelt sich hier um eine mobile Problemdiagnose-Lösung in unterschiedlichen Systemgrößen, geeignet für den Einsatz in 1G/10G/40G und 100G Netzen. Die intuitive und webbasierende Benutzeroberfläche liefert sowohl eine Echtzeit- als auch eine rückwirkende Sicht auf den Netzwerkverkehr und unterstützt einen strukturierten Workflow bei der Problemdiagnose.

Benutzeroberfläche vom Allegro Network Multimeter
Es werden wichtige Metadaten über alle Netzwerkschichten erhoben und ein PCAP-Datenmitschnitt kann permanent oder bei Bedarf selektiv aktiviert werden. Außerdem besticht das leistungsfähige Network Multimeter mit einem einmaligen Preis-/Leistungsverhältnis.
Überblick ist die halbe Miete, interessant wird es erst, wenn man ihn zum Durchblick weiterentwickelt. Mit dem Network Multimeter von Allegro Packets sehen Sie wieder den Wald vor lauter Bäumen.
Überzeugen Sie sich gern einmal in Form einer kostenfreien ![]() Teststellung davon.
Teststellung davon.
Bei Performancebeschwerden der Anwender aus entfernten Lokationen ist für die Fehleranalyse ein SNMP-Überwachungstool unerlässlich. Der Netzwerkadministrator kann hierdurch schnell erkennen, ob die WAN-Verbindungen stark ausgelastet sind.
Allerdings können Microbursts - die meist nur wenige Millisekunden anhalten - bei den typischen Abfrageintervallen von 60 Sekunden oder höher nicht von einem SNMP-Monitoring erfasst werden.

Somit bleiben Auswirkungen, wie Paketverluste, im Verborgenen - was zu einer Fehlentscheidung bei der Ursachenanalyse führen kann. Dabei sind Paketverluste Performancekiller und bereits bei Paketverlustraten von 0,5% spüren Anwender schon Performanceeinbußen.
In der aktuellen Ausgabe des Fachmagazins LANline widmet sich ein Kollege diesem Thema und erklärt, wie Paketverluste bereits bei Auslastungen deutlich unter 100% zu Klagen der Anwender über langsame Anwendungen führen können.
Den LANline-Artikel erhalten Sie unter dem nachfolgenden Link:
![]() Blinde Flecken beim SNMP-Monitoring - Die Last mit der Last
Blinde Flecken beim SNMP-Monitoring - Die Last mit der Last
Es war auch langsam an der Zeit, dass sich im Bereich WLAN-Analyse mal etwas neues auftut. Es scheint als liefere Ekahau mit dem Sidekick einen echten "Game Changer".
Der Sidekick besteht aus zwei hochperformanten 802.11ac WLAN-Adaptern, gepaart mit einer unschlagbaren Spektrum-Analysator-Karte mit 20 Sweeps pro Sekunde. Dazu kommt noch ein Akku mit einer Leistung, die einem Arbeitstag entspricht. Das ganze dann hübsch, sicher, einfach und portabel in einem Gehäuse verpackt.
Perfekt für Surveys:
|
 |
Der eingebaute Spektrum-Analysator ist so schnell und präzise, dass er im Vergleich zu anderen Spektrum Produkten eine neue Stufe von Detailreichtum aufzeigt. Laut Ekahau ist er 4x bis 10x schneller als vergleichbare Produkte und die Videos lassen wirklich darauf schliessen, dass dort eine neue Ära anbricht.
Da die Firmware des Gerätes aktualisierbar ist und das ganze direkt von Ekahau stammt, sind weitere Features möglich.
Durch den Sidekick entfällt auch die Notwendigkeit, mittels USB-Hub mehrere USB WLAN-Adapter an sein Notebook anzuschließen. Dadurch verschwindet nicht nur ein Kabel-/Adaptergestrüpp, mehrere Fehlerquellen verschwinden und der Akku von Notebook oder Tablet wird nicht belastet.
Last but not least ist es durch den Sidekick nun auch möglich, macOS im vollen Umfang für komplette Surveys zu nutzen, ohne auf etwas verzichten zu müssen bzw. Umwege über eine virtuelle Maschine gehen zu müssen.
Weitere Infos zum Ekahau Sidekick gibt es hier: ![]() Ekahau Sidekick
Ekahau Sidekick
BYOD, Cloud und IoT weichen die Netzwerkgrenzen von Firmennetzwerken auf. Klassische Netzwerkperimeter- lösungen reichen heute alleine nicht mehr aus, um Angreifer, die bereits im Netz sind, zu erkennen. Deshalb werden neue Ansätze benötigt, um Angriffe außerhalb des Überwachungsbereichs der Perimeterlösung aufzeigen zu können. Ein komplementärer Ansatz wäre, die Netzwerkinfrastruktur gemäß des Cisco Konzepts „Network as a Sensor“ selbst als Datenquelle zu nutzen. Durch Aktivierung von Netflow/IPFIX auf Routern, Firewalls, VMware usw. werden Metadaten von IP-Verkehrsströmen an ein Security-Analytics-System für die Auswertung weitergeleitet. Dieses Anomalie-Erkennungssystem kann dann verdächtige Verkehrsströme, Richtlinienverstöße und kompromittierte Endgeräte erkennen.

Die Network Traffic Analytics Sofware ![]() Scrutinizer von Plixer bietet hier vielfältige Möglichkeiten, Netzwerk- bedrohungen frühzeitig zu erkennen und ist daher die perfekte Ergänzung für existierenden Sicherheitslösungen auf Perimeter-Ebene.
Scrutinizer von Plixer bietet hier vielfältige Möglichkeiten, Netzwerk- bedrohungen frühzeitig zu erkennen und ist daher die perfekte Ergänzung für existierenden Sicherheitslösungen auf Perimeter-Ebene.
Durch Partnerschaften und Technologieintegrationen mit Firmen wie z.B. Cisco, Juniper, Gigamon, Ixia, Palo Alto Networks, Citrix, VMware, Extreme Networks, Endace, Splunk bietet Scrutinizer auch die Möglichkeit, proprietäre Metadaten der soeben aufgeführten Hersteller auszuwerten. Informationen zu den spezifischen Metadaten der Hersteller gibt es unter: https://www.plixer.com/partners/alliance-partners/
Bei Interesse stellen wir Ihnen Scrutinizer gerne vor oder fordern Sie eine ![]() Teststellung an.
Teststellung an.
Wenn Sie einen Fensterplatz im Flieger ergattert haben, erhalten Sie beim Abflug und Landung eine Sicht auf Wasserwege, das Straßennetz und sehen, wie die Orte angebunden sind und ob es aktuell zum Beispiel Staus gibt.
Aber auf dem Boden - wenn wir am meisten davon profitieren könnten - ist es meist schwierig, diese Zusammenhänge schnell zu verstehen.
Betreiber von virtualisierten Datacentern haben hier eine ähnliche Herausforderung. Es gibt viele spezialisierte Monitoringtools, die aber nicht die Weitsicht für das schnelle Auffinden von Performance-Engpässen liefern.
Dabei bietet die Vogelperspektive eine gute Methode, um aufzuzeigen, wie alles „miteinander verbunden“ ist, beziehungsweise die Möglichkeit Wichtiges von Unwichtigem zu unterscheiden.
Die ![]() AA-IPM Software von Uila liefert eine neue einzigartige Sichtweise auf die IT-Performance von virtualisierten Umgebungen und mittels Root-Cause-Analyse unterstützt es einen effizienten Workflow bei der Analyse von Performanceproblemen.
AA-IPM Software von Uila liefert eine neue einzigartige Sichtweise auf die IT-Performance von virtualisierten Umgebungen und mittels Root-Cause-Analyse unterstützt es einen effizienten Workflow bei der Analyse von Performanceproblemen.
Im nachfolgenden Anwenderbericht erhalten Sie einen Einblick, wie ein Versicherungsunternehmen in Deutschland mit der Uila-Software einen 360-Grad-Blickwinkel auf die Performance Ihres Rechenzentrums erhält.
Wer fliegt kann die Dinge und deren Zusammenhang sehen und bewerten.
Wer fliegt muss nicht enge und vollgepackte Wege gehen und kommt zwangsläufig schneller an.
Buchen Sie sich einen ![]() „Testflug“ mit der Uila AA-IPM Software.
„Testflug“ mit der Uila AA-IPM Software.
Über die letzten Jahrzehnte hat sich in der IT viel verändert und getreu dem Motto „schneller, höher, weiter“ wurden vom Client über das Netzwerk bis hin zu den Servern immer leistungsfähigere Systeme entwickelt, die die Arbeitsprozesse in den Unternehmen enorm beschleunigt haben. Diese Veränderungen sind unverzichtbare Grundlage für den Unternehmenserfolg vieler Firmen.
Leider geht diese Entwicklung, trotz ausgeklügelter Prozessmodelle wie ITIL oder eTOM, selten mit einer zuständigkeitsübergreifenden Arbeitsweise der Fachabteilungen einher. Netzwerker, Serveradministratoren und Client-Betreuer legen den Fokus auf ihren Zuständigkeitsbereich und verweisen im Fehlerfall gern mal darauf, dass ihre Überwachungssysteme auf „grün“ stehen und das Problem nicht in ihren Zuständigkeitsbereich fällt. Dummerweise können die Kollegen aus den anderen Bereichen mit ebenfalls „grünen“ Werten aufwarten und das „Schwarze-Peter-Spiel“ beginnt.
Zum Glück gibt es Unternehmen, die diese Barrieren überwinden und fokussiert die Zufriedenheit des Endanwenders in den Vordergrund stellen. Dafür ist aber eine einheitliche Sicht auf die Anwendungsperformance der Systeme erforderlich.
Eine solche Sicht liefert zum Beispiel die Lösung ![]() AA-IPM von Uila in virtualisierten Umgebungen.
AA-IPM von Uila in virtualisierten Umgebungen.
Mögen viele weitere Unternehmen diesem guten Beispiel folgen.
Häufig erfahren die IT-Administratoren erst durch ihre Anwender von Performance-Problemen und leider nicht von den eigenen Monitoring-Tools. Allerdings erschweren die typisch vagen Aussagen, wie z.B. „es dauert ewig“, die zielorientierte Ursachenanalyse. Und die hohe Komplexität in den stark virtualisierten Rechenzentren macht eine Analyse auch nicht einfacher.

Hier fehlt es meist an einer integrierten, korrelierten Ende-zu-Ende-Sicht über alle Ebenen. Wir empfehlen hier unseren Kunden den Einsatz einer Full-Stack-Monitoring-Lösung von der Firma Uila. Diese Software bietet:
- Das Monitoring von den physikalischen und virtuellen Systemen
- Die Überwachung aller Teile der Datacenter-Infrastruktur, von Netzwerk-, Storage- bis zur Applikationsebene
- Eine Beurteilung der gesamten Kette, angefangen bei der Infrastruktur über die Anwendung bis zu der aktuellen End-User-Experience
- Eine Korrelation der unterschiedlichen Ebenen inkl. Visualisierung der Rechenzentrumtopologie und den Abhängigkeiten
- Eine Root-Cause-Analyse für eine effiziente Analyse von Performanceproblemen
Im  Bericht des IT-Analysten Edwin Yuen von der Enterprise Strategy Group werden die Vorzüge des Full-Stack-Monitorings für Performance-Monitoring in Rechenzentren beschrieben. Das besondere an der Uila Software ist die Deep-Packet-Inspection-Funktion und die Visualisierung der Performance-Daten. Das agentenlose Virtual Smart Tap (VST) scannt den Netzwerkdatenverkehr an den virtuellen Switchen und mittels der integrierten Datenbank von über 4.000 Protokollen und Applikationen werden wichtige Applikations- und Netzwerkmetadaten berechnet. Für sogenannte „Text-on-Wire“-Anwendungen findet sogar eine Transaktionsanalyse statt. Und gemäß „ein Bild sagt mehr als tausend Worte“, liefert die Uila Benutzeroberfläche „einen Roman“ aus. Das intuitive GUI vereinfacht erheblich den Workflow bei der Analyse von Performanceengpässen.
Bericht des IT-Analysten Edwin Yuen von der Enterprise Strategy Group werden die Vorzüge des Full-Stack-Monitorings für Performance-Monitoring in Rechenzentren beschrieben. Das besondere an der Uila Software ist die Deep-Packet-Inspection-Funktion und die Visualisierung der Performance-Daten. Das agentenlose Virtual Smart Tap (VST) scannt den Netzwerkdatenverkehr an den virtuellen Switchen und mittels der integrierten Datenbank von über 4.000 Protokollen und Applikationen werden wichtige Applikations- und Netzwerkmetadaten berechnet. Für sogenannte „Text-on-Wire“-Anwendungen findet sogar eine Transaktionsanalyse statt. Und gemäß „ein Bild sagt mehr als tausend Worte“, liefert die Uila Benutzeroberfläche „einen Roman“ aus. Das intuitive GUI vereinfacht erheblich den Workflow bei der Analyse von Performanceengpässen.
Am besten überzeugen Sie sich von der 360-Grad Cockpitansicht der Uila Software indem Sie eine
kostenfreie ![]() Teststellung bei uns anfordern.
Teststellung bei uns anfordern.
Welcher IT-Administrator kennt das nicht: Ein Anruf eines Anwenders, der anfängt mit „warum ist alles so langsam?“. Diese oder ähnliche Fragestellungen hat jeder schon mal für die unterschiedlichsten Performanceprobleme auf den Schreibtisch bekommen. Wenn der Anrufer dann noch zum Management gehört, fängt jeder hektisch an, im eigenen Fachbereich das gemeldete Problem zu analysieren. Niemand möchte den „Schwarzen Peter“ zugeschoben bekommen und versucht, seine Unschuld - mit den ihm verfügbaren Informationen - zu belegen.
Selbst wenn das Problem von alleine wieder verschwindet, tickt da eine Zeitbombe, die irgendwann mal wieder hochgehen kann.
Gerade bei dieser Art von sporadischen Performancestörungen kann nur mittels einer schrittweisen, strukturierten Vorgehensweise nach dem Ausschlussverfahren dem Problem auf den Grund gegangen werden. Leider gibt es (noch) nicht das ultimative Werkzeug, das leicht bedienbar ist, alles kann, proaktiv Fehler erkennt und sogar Lösungsvorschläge anbietet. Wunschdenken und Wirklichkeit liegen hier weit auseinander.
Also was ist bei der Fehlersuche von sporadischen Problemen zu beachten:
- Genaue Fehlerbeschreibungen erstellen. Erst soll das Problem verstanden werden bevor man mit der Analyse beginnt.
- Versuchen, die sporadischen Probleme auf Teile der IT-Infrastruktur, welche eine Ursache darstellen können, zu reduzieren. Hierfür können dann Daten mit maximaler Detailtiefe erhoben werden.
- Fokus der Performance-Kennzahlen aus dem Bereich Qualität. Typischerweise erheben die gängigen Monitoring-Systeme Kennzahlen aus dem Bereich Quantität (z.B. CPU- und Leitungsauslastung) aber häufig fehlt es an Qualitätskennzahlen wie z.B. Paketverluste und Applikationsantwortzeit.
- Eingesetzte Analysetools sind vom „Problem“ abhängig zu machen und nicht umgekehrt.
- Nach Eingrenzung des Problembereichs sind Experten aus dem jeweiligen Bereich hinzuziehen.
Ohne ausreichend Zeit, die richtigen Werkzeuge und die notwendigen Kenntnisse lassen sich in den heutigen, komplexen und redundanten IT-Infrastrukturen sporadische Performanceprobleme nur schwer analysieren und lösen.
Wenn Sie in dieser Situation eine „unabhängige“ Unterstützung benötigen, dann sind Sie bei uns gut aufgehoben. Gerne übernehmen wir auch das „Management“ von Eitelkeiten der Beteiligten.
Mit unserem langjährigen & fokussierten Wissen, garniert mit unserem umfangreichen Fuhrpark an Analysetools, bietet unsere ![]() GeNiAnalyze Dienstleistung eine schnelle und flexible Unterstützung bei der Analyse von Performanceproblemen.
GeNiAnalyze Dienstleistung eine schnelle und flexible Unterstützung bei der Analyse von Performanceproblemen.

Willkommen zurück zu unserer Blog-Serie über GeNiEnd2End Skripting!
Als letzten Teil der Serie stelle ich ein paar unserer Skripte, die wir selbst in Betrieb haben, vor.
Viele der Skripte sind zum Kennenlernen der Skriptingsprachen erstellt worden und dann später für den produktiven Einsatz überarbeitet worden. Die Skripte Beisner Solar und Temperatur Erfassung dienen ausschließlich dazu, Messwerte für unsere Demosysteme zu sammeln.
Die Darstellung der Messwerte gibt es natürlich nicht nur für einen Tag, sondern auch Wochen, Monat, Jahr - ganz nach Wunsch dann im GeNiEnd2End.
Ab GeNiEnd2End Version 5.2 (Geplant für Ende des Jahres) ist auch wieder die Aggregierung von Messwerten enthalten.
Beisner Solar:
Beisner Druck ist ein Nachbarn in Sichtweite unserer Hauptniederlassung und seitdem deren Standort eine moderne Solaranlage installiert hat, zeigen sie die dadurch gewonnenen Kilowatt auf ihrer Website an. Ein Skript holt die Messwerte von der Website ab und liefert diese in GeNiEnd2End. Die Chart zeigt ausschließlich die aktuelle Leistung der Solaranlage an.
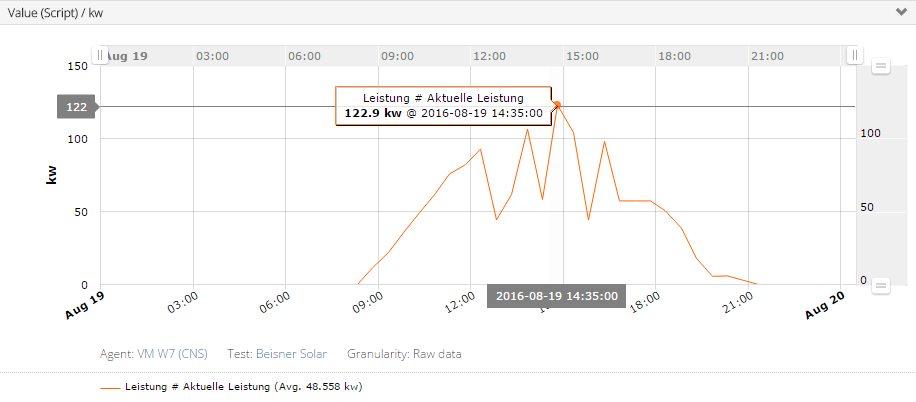
Temperaturerfassung:
Seit einigen Jahren zeichnen wir die Temperaturwerte einiger Büroräume auf und nutzen es auch zur Notifikation wenn Schwellwerte überschritten werden.
Sofern die Temperatur des Serverraums einen Schwellwert überschreitet wird ebenfalls eine eMail verschickt, direkt durch das Skript.
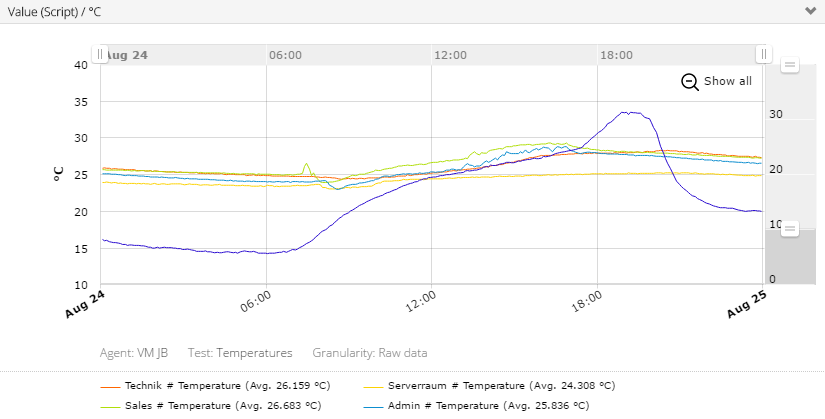
Ja, der Serverraum ist zu warm, die große Klimaanlage ist defekt und der vorrübergehende Ersatz schafft leider keine ausreichende Luftzirkulation im Raum. Die blaue Linie ist die Aussentemperatur, in Anbetrachtet dessen, hat sich die kleine Aushilfsklimaanlage doch ganz gut gehalten (Serverraum ist die gelbe Linie).
Am Ort der Messung staut sich die Hitze, die Position wurde mit Absicht gewählt :), und zeigt somit immer den schlechtesten Wert im ganzen Raum an.
IBM Notes:
Entstanden ist das Skript, um zu zeigen, dass die Bilderfassung stabil und schnell funktioniert. Inzwischen ist das Skript seit 5 Jahren durchgängig als Liefrant für Messwerte aktiv.
Es hat uns auch schon geholfen, Performanceveränderungen aufzuzeigen und den Verursacher ausfindig zu machen. (Siehe Link unten)
Der inzwischen benutzte Roboter hat einen großen Nachteil: Er verfügt über keine richtige Grafikkarte und das spürt man bei dem Benutzen des Notes Clients bzw. das spiegeln auch die Messwerte wieder. Die kurzen Ausfälle sind gewollt, um auch Fehlerstände zu zeigen.
Von 22:00 bis 06:00 ist eine Primetime aktiv, also wird in dieser Zeit keine Messung durchgeführt.
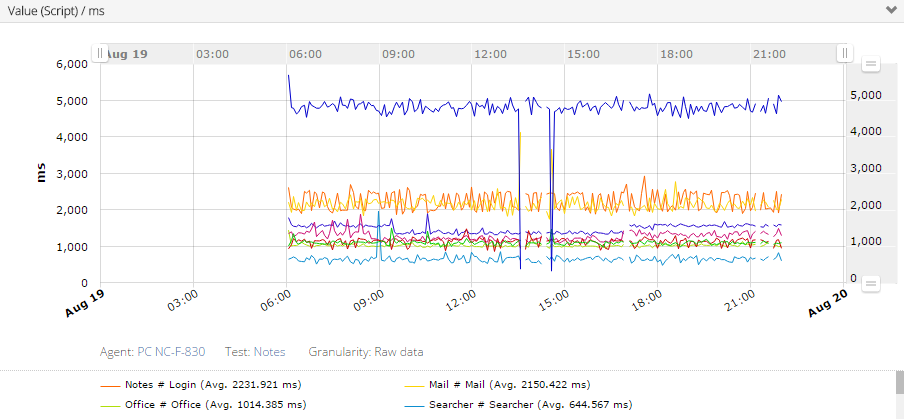
Link zum alten Blog Eintrag (Alte Messwerte): Blog Eintrag zu Notes und CNS
DHCP + DNS + Traceroute:
Aus Kundenwünschen bzw. durch Bedarfserkennung entstanden und inzwischen Standard Skripte von GeNiEnd2End Application. DHCP zeigt die DHCP Offers an und wie viele Server auf die Anfrage geantwortet haben und in welcher Zeit.
DNS zeigt an, wie lange die DNS-Abfrage gedauert hat und der Traceroute-Test zeigt Veränderungen an der Anzahl der Hops auf.
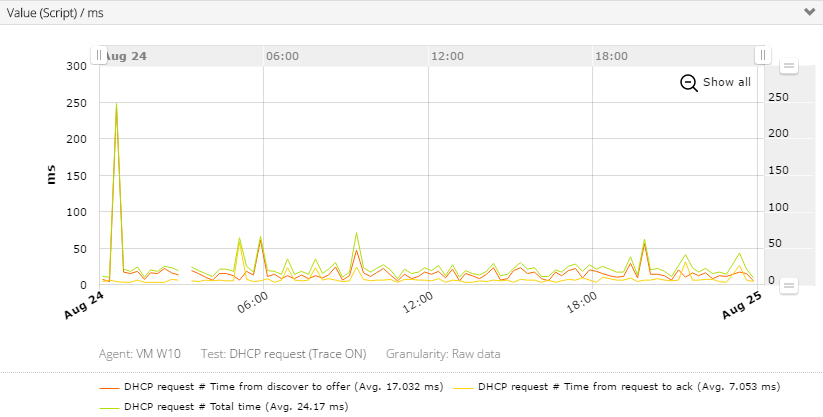 |
 |
 |
| DHCP |
DNS |
Traceroute |
File Transfer (SMB/CIFS Dateiübertragung):
Probleme mit dem SAN bzw NAS erkennen? Kein Problem! Die SMB Skripte führen einen Dateitransfer oder Transfer mehrerer Dateien durch. Die Größe der Datei/en ist angebbar, Messwerte sind jeweils die Dauer und Geschwindigkeit von Up- und Download.
 |
 |
| Eine Datei 10MB |
100 Dateien je 20KB |
Anderes:
Skripte für Kunden, um Verfügbarkeit bzw. Performance für interne Websites, Online Banking, Zimmerreservierungen, Messungen in und rund um Citrix aufzuzeigen. Sogar LTE-Verbindungsmessungen haben wir bereits durchgeführt. Natürlich alles mit Alarmierung durch GeNiEnd2End bei Nichtverfügbarkeit oder unter- bzw. überschreiten von Schwellwerten.
Natürlich gibt es auch vieles, was nur internen Bedarf oder Spielereien abdeckte.
Darunter verschiedene Skripte die Commandos per SSH ausführen und deren Durchführung + benötigte Laufzeit dann aufgezeichnen. Erkennung, ob Backups liefen, wie groß diese Anwuchsen pro Tag, SNMP-Abfragen usw., ...
Auch hier bleibt die Devise "The sky is the limit".
Das war nun allerdings der letzte Teil dieser Blogbeitrag-Serie. Hoffentlich konnten wir Ihnen bei Ihrem Skript behilflich seien.
Anderesfalls kontaktieren Sie uns!
Willkommen zurück zu unserer Blog Serie über GeNiEnd2End Skripting!
Heute behandeln wir das Back-End Skripting und was dort beachtet werden sollte.
Was sind Back-End Skripte?
Back-End Skripte interagieren normalerweise nicht mit dem Desktop in irgendeiner Art.
Sie laufen im Hintergrund und behindern keinen an dem System arbeitenden Benutzer.
Es gibt keine Grenzen was gemessen werden kann, von Router Verbindungsstatistiken hin zu wie lange dauern SQL-Abfragen.
Was immer Sie messen wollen, Sie können es sich selber bauen.
Aber fangen Sie nicht einfach Hals über Kopf damit an, erfinden Sie das Rad nicht neu! Vielleicht gibt es bereits etwas da draußen, das Ihnen die Messwerte liefert, die Sie haben wollen.
Die AutoIt und Python Communities haben bereits viele Module / Libraries, die oft genau das tun / können was man möchte oder Ihnen dabei behilflich sein können, schneller an das Ziel zu kommen. Also schauen Sie zuerst in den Communities.
Wenn es bereits ein anderes Programm gibt, was Ihnen die Messwerte liefert die Sie gerne in GeNiEnd2End haben möchten, dann ist das gar kein Problem! Unsere AutoIt / Python Skripte benutzen manchmal auch im Betriebssystem enthaltene Tools (Ping, tracert, nslookup) oder andere herunterladbare Programme (z.B. PuTTY) um die Messwerte zu bekommen und diese Daten werden dann verarbeite, um nur die gewünschten Daten zu erhalten.
Sie müssen sich nur an die Regeln halten wie der GeNiAgent die Resultate bekommen möchte.
-
Schreiben Sie ein Log, vielleicht mit einer "Debug" Einstellung, das ein erweitertes Logging aktiviert wenn Sie es benötigen. Dieses kann sehr hilfreich sein, um schnell Probleme zu identifizieren, aufzuzeigen, wo es hängt bzw. welche Unterschiede es zwischen Programmierumgebung und der kompilierten Version gibt. Der GeNiAgent sucht ausserdem nach einem "error.log" und "detail.log" im Skript Ordner und lädt diese auf den GeNiEnd2End Server hoch. Diese sind dann direkt in der Weboberfläche einsehbar.
-
Wenn Sie ein Programm benutzen müssen was auf dem Desktop erscheint, sollten Sie es versteckt starten.In AutoIt ShellExecute gibt es eine Option namens showflag, diese kann auf "@SW_HIDE" gesetzt werden.In Python können Sie eine hidden flag an den Subprozess anhängen, siehe Hilfe für Informationen.
-
Seien Sie sich bewusst, das wenn ein Skript im Hintergrund über den GeNiAgenten gestartet wird, es andere Rechte haben kann als wenn Sie es manuell starten. Somit könnten andere Probleme auftreten. Normalerweise beeinflusst das die meisten Skripte nicht. Wenn Sie wirklich Admin Rechte benötigen, können Sie AutoIt anweisen, diese mit der "#RequireAdmin" Flag am Beginn des Skripts anzufragen - aber dann sollte der GeNiAgent ebenso mit administrativen Berechtigungen gestartet werden.
- Wenn Sie viele Transaktionen nacheinander durchführen oder Sie die Packet Trace / CNS Option benutzen, sollten Sie darauf achten, nach jeder Transaktion 5 Sekunden Pause einzuhalten bevor die nächste Transaktion gestartet wird.
- Wenn Sie ein externes Programm zum Erhalt von Messwerten nutzen, überprüfen Sie diese auf Plausibilität und wie sich der Messwert zusammensetzt.
Nun können Sie durch die GeNiEnd2End Hilfe-Sektion der Skripting Sprache gehen, die Sie benutzen wollen. Diese können Ihnen bei weiteren Vorgehensweisen helfen.
Im letzten Blogbeitrag dieser Serie zeigen wir Ihnen einige unserer Skripte und auch welche, die es inzwischen in die Standardskripte geschafft haben.
Willkommen zurück zu unserer Blog Serie über GeNiEnd2End Skripting!
Heute behandeln wir das GUI basierte Front-End Skripting und was dort beachtet werden sollte.
Skripte, die mit dem Desktop interagieren, sind einfacher in AutoIt zu erstellen, dadurch aber nur auf der Windows-Platform lauffähig.
Die Hardware des Roboters sollte der von normalen Benutzern entsprechen, ansonsten werden die Messergebnisse von denen der normalen Benutzer abweichen. Es sollte eine physikalische Hardware genommen werden und keine virtuelle Maschine. Schliesslich geht es darum, Probleme zu finden, die ein Benutzer haben könnte und Messwerte zu bekommen, wie lange eine Transaktion für einen Benutzer dauert.
Jede Messung, die wie ein Benutzer agieren soll, sollte mit einer Klickstrecke starten. Diese enthält alle Schritte die das Skript durchführen soll, und man setzt dort die Messpunkte bzw. kann sie dadurch herausfinden. Diese hilft später beim Auffinden von Problemursachen, wenn das Skript an einer spezifischen Stelle hängen bleibt.
Beispiel Klickstrecke von einem unserer Produktionsskripte:
![]() PDF Klickstrecken Dokumentation
PDF Klickstrecken Dokumentation
Best Practices
-
Schreiben Sie ein Log, vielleicht mit einer "Debug" Einstellung, das ein erweitertes Logging aktiviert wenn Sie es benötigen. Dieses kann sehr hilfreich sein, um schnell Probleme zu identifizieren, aufzuzeigen, wo es hängt bzw. welche Unterschiede es zwischen Programmierumgebung und der kompilierten Version gibt. Der GeNiAgent sucht ausserdem nach einem "error.log" und "detail.log" im Skript Ordner und lädt diese auf den GeNiEnd2End Server hoch. Diese sind dann direkt in der Weboberfläche einsehbar.
-
Hat die Applikation eine sich schnell verändernde Oberfläche (viele Änderungen am GUI)? Wenn das so ist, sollten Sie versuchen, Fenstertexte (Titel / Inhalt) für die Messungen zu nehmen, so dass Ihr Skript nicht so einfach von GUI-Änderungen beeinflusst wird.
-
Wenn Sie die Bildersuche (Image search) benutzen müssen:Dann sollten Sie versuchen, die Bildausschnitte so neutral wie möglich zu machen. Das heisst: Nehmen Sie Bildausschnitte von GUI-Elementen, die sich so wenig wie möglich verändern können oder einfach zu finden sind, auch wenn sich die Lokation etwas verändert hat. Die Größe des Bildausschnitts der gesucht wird, sollte so klein wie möglich sein. Dadurch ist die Chance höher, dass er auch nach Änderungen gefunden wird. Die Screenshots sollten auf einen Roboter erstellt werden, so das keine Farbunterschiede oder andere Eigenheiten vorhanden sind.
-
Wird die Applikation anzeigen, wenn etwas fehlschlägt - z.B. Fehlermeldungen \ Fehlerbehandlung?Sie sollten überprüfen, ob nach einer fehlgeschlagenen Messung Fehlermeldungen bestätigt werden müssen oder was passiert, wenn die Applikation sich nicht richtig geschlossen hat. Behalten Sie das im Hinterkopf und skripten Sie für diese Fälle. Schreiben Sie ein "error.log" und "detail.log".
-
Können Sie die Schritte nur mit Mausklicks vornehmen oder auch mit Tastaturkürzeln?Sie können Tastatureingaben senden, das ist meistens der bessere Weg, um mit dem Desktop zu interagieren. Dies gelingt natürlich nur, wenn es die selbe Funktion ist wie bei einem Mausklick.Wenn Sie einen Mausklick machen müssen und die Lokation des Klicks sich möglicherweise ändert, machen Sie eine Bildersuche (Image search). Dazu suchen Sie nach einem Stück des Buttons und klicken dann darauf, so das Sie nicht den falschen Button anklicken, weil er sich eventuell leicht bewegt hat.Wenn Ihre Applikation keine IDs / Namen der Designelemente vergibt, können Sie diese auch direkt ansprechen. (Überprüfen Sie das mit dem AutoIt Window Info Programm)
- Wenn Sie viele Transaktionen nacheinander durchführen oder Sie die Packet Trace / CNS Option benutzen, sollten Sie darauf achten, nach jeder Transaktion 5 Sekunden Pause einzuhalten bevor die nächste Transaktion gestartet wird.
Dieses Beispiel Skript läuft auf einem Roboter, es ist ein AutoIT Skript was mit dem IBM Notes Client 8.5 und 9.0 ohne größere Änderrungen agiert.
Nächstes Mal befassem Wir uns mit Back-End Skripting.
Willkommen zu dieser kurzen Blog Serie über ![]() GeNiEnd2End Application - HowTo / Best Practices Scripting!
GeNiEnd2End Application - HowTo / Best Practices Scripting!
Diese Blog Serie soll Ihnen zeigen, worauf Sie beim Erstellen eines Skripts achten müssen und welche Skript- / Programmiersprache zu welchem Nutzen passt. Die Best Practices sollen Ihnen helfen, einige Standardprobleme und Fehler zu vermeiden.
In diesem Blogeintrag behandeln wir die generellen Skripting Richtlinien und welche Skript- / Programmiersprache am besten zu was passt.
Zuerst sollten Sie sich folgende Fragen stellen:
- Was wollen Sie mit dieser Messung erreichen?
- Was ist die Platform der Applikation?
- Windows
- GeNiJack
- Beides
- Was für ein Typ ist die Applikation?
- Webseite
- Selbst angepasstes GUI
- GUI vom Hersteller
- Anderes
- Was für Messpunkte soll das Skript haben?
- Gibt es schon ein Default Skript was Sie bearbeiten könnten?
Welche Default Skripts es in ![]() GeNiEnd2End Application gibt finden Sie in der Hilfe unter Sektion "Application Measurement -> Default Scripts".
GeNiEnd2End Application gibt finden Sie in der Hilfe unter Sektion "Application Measurement -> Default Scripts".
Featurevergleich AutoIt und Python:
| AutoIt | Python | |
| Plattform | Windows | Windows / GeNiJack |
| GUI Testing | Ja und es ist einfach | Möglich aber nicht empfohlen / Nicht auf GeNiJack |
| Webseiten Testing | Ja, komplett | Ja aber nur Downloadzeit und Änderungen |
| Empfohlen für | Anfänger / Professionals | Professionals |
| Messgenauigkeit | Gut | Am besten |
| Feature Scope | Gut / viele Module verfügbar | Am besten / volle Programmiersprache |
Wenn Ihnen Skripting / Programmierung noch neu ist, können Sie am einfachsten mit AutoIt und einem einfachen Skript starten.
Wenn Sie bereits in einer professionellen Programmiersprache erfahren sind, hat Python einen grösseren Funktionsumfang und wird Ihnen eher zusagen.
Die "Tu es nicht" Aussagen:
- Vergessen Sie nicht die CNS Option, die Ihre Messzeiten aufbrechen kann in Client / Network / Server Zeit.
- Unterschätzen Sie nicht die Power von AutoIt, es bietet viele Features, ist einfach zu benutzen und stabil.
Wenn Sie bereits eine spezielle Sprache für GUI basierte Tests benutzen oder Sie einfach eine andere Sprache nutzen wollen, dann können Sie diese benutzen und die Ergebnisse an den GeNiAgent übergeben. In diesem Falle kontaktieren Sie uns für Hilfe: support@netcor.de
Bei dem nächsten Mal gehen wir die GUI basierten Front-End Skripting Tests an und was man dabei beachten sollte.
![]() GeNiEnd2End Application
GeNiEnd2End Application
![]() GeNiJack
GeNiJack
![]() GeNiEducate
GeNiEducate
Alles neu macht der Mai, das trifft dieses Jahr auch auf dem NetScout AirCheck zu.
Endlich gibt es das neue AirCheck G2 Modell mit 802.11ac WLAN-Adapter und weiteren Neuheiten.
Neuerungen:
Das Beste von dem Vorgängermodell wurde übernommen, dazu gehört:
|
 |
Sie können sich den AirCheck G2 hier in einer virtuellen Tour ansehen: ![]() Virtuelle Tour
Virtuelle Tour
Unqualifizierte Anwenderbeschwerden wie „bei mir ist alles langsam“, gehören sprichwörtlich zu der berühmten Spitze des Eisbergs. Sichtbar ist lediglich der kleinere Teil eines Eisbergs, während der wesentlich größerer Teil, der Verursacher des Performanceproblems, unter der Wasseroberfläche verborgen ist.
Gründe von schlechten Antwortzeiten können vielseitig sein. Es kann die Infrastruktur sein, wie z.B. ein Engpass bei CPU/Speicher der VM/Hosts, die Netzwerkbandbreite/Latenz und oder Engpass im Storage. Es kann aber durchaus bei komplexen Multi-Tier-Anwendungen an den Abhängigkeiten zwischen Anwendungen und/oder nicht optimal designte Applikationen liegen.
Hinzu kommt noch, dass der erhöhte Komplexitätsgrad innerhalb von virtualisierten Umgebungen die strukturierte und schnelle Ursachenanalyse bei Performanceengpässen erschwert. Die große Herausforderung für den IT-Betrieb liegt darin, für den Zeitraum der Beschwerde, eine Beziehung herstellen zu können zwischen der
- Anwendungsebene und der virtuellen Infrastruktur wie z.B. VMware, Hyper-V und KVM und anschließend zwischen
- der virtuellen Infrastruktur und der physikalischen Infrastruktur bestehend aus Host-Hardware und die Netzwerk- und Storage-Infrastruktur.
Ein wesentlicher Ausgangspunkt für eine effiziente Ursachenanalyse ist die Anwenderbeschwerde bezüglich der Applikationsantwortzeit. Allerdings liefern die klassischen Systemmonitoringtools volumenbasierte Performancedaten, wie z.B. Auslastung der CPU/Speicher/Storage, sodass hier der objektive Bezug zum gemeldeten Performanceproblem fehlt. Nur Performancemetriken, wie z.B. Applikationsantwortzeit, Transaktions-volumen, TCP-Session-Metriken liefern die notwendigen Informationen für eine Ende-zu-Ende Performanceanalyse.

Uila AA-IPM Application Performance Ansicht
Eine Möglichkeit diese Metadaten zu erheben ist Packet-Capturing. Einen ausgesprochen interessanten Ansatz geht hier die Firma Uila mit dem Produkt ![]() AA-IPM. Mittels eines Virtual Smart Taps – eine „lightweight VM“, die sich am virtuellen Switch andockt – wird der Datenverkehr in den Richtungen Nord-Süd und Ost-West mittels DPI-Technologie analysiert. Dieser „agentenlose“ Ansatz ermöglicht eine Performance-Analyse aller virtualisierten Anwendungen - auch der VMs die am gleichen virtuellen Switch angeschlossen sind. Dadurch, dass das Virtual Smart Tap die Datenpakete direkt vom virtuellen Switch abgreift, erhält man einen tiefen Einblick in das Kommunikationsmuster und die Netzwerk- und Applikationsmetriken.
AA-IPM. Mittels eines Virtual Smart Taps – eine „lightweight VM“, die sich am virtuellen Switch andockt – wird der Datenverkehr in den Richtungen Nord-Süd und Ost-West mittels DPI-Technologie analysiert. Dieser „agentenlose“ Ansatz ermöglicht eine Performance-Analyse aller virtualisierten Anwendungen - auch der VMs die am gleichen virtuellen Switch angeschlossen sind. Dadurch, dass das Virtual Smart Tap die Datenpakete direkt vom virtuellen Switch abgreift, erhält man einen tiefen Einblick in das Kommunikationsmuster und die Netzwerk- und Applikationsmetriken.
Eine weitere Besonderheit der Uila Software ist das integrierte Analytik Modul, das die Applikationsperformance mit der Performance von der virtuellen und physikalischen Infrastruktur korreliert, wodurch die Fehler- Ursachen-Analyse wesentlich vereinfacht wird. Oder anders ausgedrückt, Ihnen den Teil des Eisbergs der unter der Wasseroberfläche liegt, sichtbar macht.
Fehleinschätzungen und Kollisionen wie der Untergang der Titanic können somit vermieden werden. Ahoi!
Analysen von Performance-Engpässen in virtuellen Infrastrukturen ist oft eine knifflige Aufgabe. Es fängt schon damit an, subjektive Beschwerden der Anwender sinngebend mit den Performance-Metriken von VMware zu verknüpfen. Unabhängig von der Objektivität der Wahrnehmung des Anwenders geht es darum, eine Brücke zu bauen zwischen
- der Maßeinheit Sekunde, die vom Anwender als Applikationsantwortzeit wahrgenommen wird und
- die Maßeinheiten %, Mbyte, IOPS, Millisekunde usw. die im vCenter abgerufen werden können.
Für eine strukturierte Performanceanalyse ist es aber wichtig, dass eine Beziehung zwischen den unterschiedlichen Messgrößen hergestellt werden kann; wobei das Ganze noch mit dem Zeitraum der Beschwerde zu korrelieren ist. Diese unverbundene Ansammlung von Informationen erschwert die Ursachenbestimmung des Performanceengpasses erheblich. Außerdem fehlt uns oft hierfür die notwendige Zeit und Ruhe zur Durchführung einer effizienten Performanceanalyse.
Damit kommen wir dann zu der tatsächlichen Herausforderung: Wie kann aus dieser Informationsmenge zwischen trivial und bedeutenden Informationen unterschieden werden, sodass daraus Wissen für die Ursachenanalyse entsteht?
Ein interessanter Ansatz für VMware liefert hier die Firma Uila (spricht sich „wee-lah“). Mittels Uila ![]() AA-IPM (Application-Aware – Infrastructure Performance Management) wird die unverbundene Ansammlung von Informationen organisiert und es werden Abhängigkeiten zwischen Applikationsantwortzeiten und der Infrastrukturauslastung aufgezeigt. Mit dieser Vernetzung der Informationen verliert das Performance-Troubleshooting von virtuellen Infrastrukturen endlich ihren Schrecken.
AA-IPM (Application-Aware – Infrastructure Performance Management) wird die unverbundene Ansammlung von Informationen organisiert und es werden Abhängigkeiten zwischen Applikationsantwortzeiten und der Infrastrukturauslastung aufgezeigt. Mit dieser Vernetzung der Informationen verliert das Performance-Troubleshooting von virtuellen Infrastrukturen endlich ihren Schrecken.
Beobachtete, subjektive Performanceengpässe eines Anwenders können mit Uila jetzt objektiv bewertet bzw. die Grundursache(n) schnell ermittelt werden. In der Praxis bedeutet das, dass bei einer Anwenderbeschwerde über lange Applikationsantwortzeiten für eine Oracle Datenbank, die Ursachenanalyse in der Zukunft wie folgt laufen könnte:

Vorgehensweise mit Uila AA-IPM
- Zeitraum der Beschwerde auswählen
- In der Alarmübersicht gibt es tatsächlich einen Eintrag über lange Antwortzeiten der Oracle 11g-n2 Datenbank
- In der Ursachenanalyse wird u.a. ersichtlich, dass wegen hoher IOPS-Werte des Storagesystems, hohe Antwortzeiten in der Datenbank entstehen
- In der detaillierten Storageanalyse wird der wahre Verursacher der hohen IOPS-Werte des Datastore1 (4) aufgeführt, es ist die Oracle Datenbank 11g-n1
Nicht strukturierte Informationen gewinnen erst an Aussagekraft, wenn sie ins Verhältnis zu anderen gesetzt werden. Genau hier unterstützt das Analytikmodul von Uila AA-IPM den IT-Verantwortlichen bei der Behebung von Performanceproblemen.
Ohne Uila AA-IPM ist die Performanceanalyse in VMware wie das Suchen der Nadel im Heuhaufen.
Bei der Netzwerkanalyse in 1G/10G-Netzen werden für die Bewältigung von großen Datenvolumina immer häufiger sogenannten Network Packet Broker eingesetzt. Diese Switches können unterschiedlichen Datenströmen u.a. aggregieren, regenerieren und/oder filtern. Um bei komplexeren Switch-Konfigurationen nicht den Überblick zu verlieren, sagt ein Bild mehr als tausend Worte.

Infinicore Domain Designer
Mit dem neuen, web-basierten Flow Domain Designer des ![]() FlowDirector-640 von Infinicore können Sie jetzt per Drag und Drop die gewünschte Konfiguration einfach „zeichnen“. Mittels unterschiedlichen Shapes wie z.B. Ingress-Ports, Egress-Ports, Aggregator, Replicator oder Filter kann die benötigte Switch-Konfiguration per Drag und Drop im Flow Domain Designer erstellt werden. Somit können komplexe Konfigurationen in übersichtlichen Netzwerkdiagrammen visualisiert und für Dokumentationszwecke können diese Netzwerkdiagramme sogar exportiert werden (PDF).
FlowDirector-640 von Infinicore können Sie jetzt per Drag und Drop die gewünschte Konfiguration einfach „zeichnen“. Mittels unterschiedlichen Shapes wie z.B. Ingress-Ports, Egress-Ports, Aggregator, Replicator oder Filter kann die benötigte Switch-Konfiguration per Drag und Drop im Flow Domain Designer erstellt werden. Somit können komplexe Konfigurationen in übersichtlichen Netzwerkdiagrammen visualisiert und für Dokumentationszwecke können diese Netzwerkdiagramme sogar exportiert werden (PDF).
Der FlowDirector-640 verfügt über 48 x 1G/10G SFP/SFP+ und 4 x 40G QSFP Ports und ist mit der aktuellsten Generation von Prozessoren und Switch-Technologien ausgestattet und macht es einfach, Datenströme von Span-Ports und Taps zu aggregieren, zu kopieren, zu filtern und diesen gezielt zu den Monitoring-Tools weiterzuleiten.
Bei Interesse, zögern Sie nicht, uns für eine Produktevaluierung zu kontaktieren.
Es gibt eine Vielzahl von Tools für die virtuelle Performance- und Kapazitätsanalyse. Sie überwachen die CPU-, Speicher-, Storage- und Netzwerkleistung indem sie das vCenter hierfür anzapfen. Mit den Performancemetriken Bytes in/out, Pakete in/out und Fehlerzähler für die physikalischen und virtuellen Interfaces liefern diese Informationen nur einen eingeschränkten Nutzen beim Troubleshooting von Fehlersituationen. Zum Beispiel wenn auf einem Hostadapter eine erhöhte ausgehende Netzwerklast zu verzeichnen ist; ist das jetzt ein Problem?
Sofern ein System-Monitoring zum Einsatz kommt, kann hiermit dargestellt werden, dass die Netzwerklast ungewöhnlich hoch ist, allerdings auch nicht mehr.
Man weiß nicht:
- was das für ein Datenverkehr ist
- wer ist/sind der/die Verursacher(n)
- welche Auswirkung diese zusätzliche Last auf die Latenz für den anderen Datenverkehr auf diesem Host hat
Mit anderen Worten: Für eine effiziente Fehlererkennung und Behebung fehlen wichtige Informationen.
Was müssen Sie wirklich wissen über Ihr virtuelles Netzwerk?
Reine Auslastungsinformationen bei der Analyse von Performanceproblemen in virtuellen Netzwerken reichen nicht mehr aus. Es werden netflow-ähnliche Daten benötigt, wie z.B.:
- wer kommuniziert mit wem?
- welche Ports/Protokolle werden genutzt?
- wann hat die Kommunikation stattgefunden?
- wie groß war das Datenvolumen?
Weitere wichtige Informationen sind:
- welche Abhängigkeiten bestehen zwischen Applikationsantwortzeiten und der Auslastung der Infrastruktur (Host, Netzwerk, Storage)?
- welche VMs erleiden ungewöhnlichen hohen virtuellen Netzwerklaufzeiten?
- wer verursacht die hohe Laufzeiten?
- physikalischer Switch
- Netzwerkkarte des Hosts
- virtueller Switch
- virtuelle Netzwerkkarte
Mittels dieser Detailinformationen können schnell und einfach Performanceengpässen in virtuellen Netzen diagnostiziert und proaktiv Applikationsperformanceproblemen verhindert werden.
Und wie erhält man diese Daten? Mit ![]() Uila AA-IPM.
Uila AA-IPM.
Ursachenanalyse mit Uila AA-IPM
Mit der Uila Software können Performanceschwachstellen in der vSphere-Infrastruktur in Echtzeit oder auch historisch aufgezeigt werden. Uila liefert eine direkte Korrelation zwischen der Applikationsantwortzeit und der Auslastung der Infrastruktur. Mittels einer Virtual Smart Tap (vST) Gast-VM wird der Datenverkehr zwischen den VMs analysiert - in dem es die Daten am vSwitch analysiert. Es werden nur Metadaten, wie z.B. Applikationsantwortzeit und Kommunikationsbeziehungen, erhoben.

Uila AA-IPM Sankey-Diagramm
Über die zentrale Managementsoftware können die virtuellen Switche ausgewählt werden, an dem das Virtual Smart Tap die Deep Packet Inspection durchführen soll. Diese Informationen werden mit den Auslastungsdaten die vom Virtual Information Manager (vIM) eingesammelt werden im Uila Portal korreliert. Der vIM sammelt Performancedaten der Infrastruktur (Host, Netzwerk, und Storage), die vom vCenter verwaltet werden, und speichert diese für die forensische Analyse in einer Hadoop Analytik Plattform ab.
Mit den Sankey-Diagrammen zur Visualisierung der Datenflüssen und der Applikationstopologiemap erhält der System- und Netzwerkadministrator einen globalen Einblick in möglichen Performanceengpäßen, was zu einer effizienteren Fehler- und Ursachenanalyse führt.
Interessiert? Dann zeigen wir Ihnen gerne per Websession die ![]() Uila Aplication-Aware Infrastructure Performance Management Software.
Uila Aplication-Aware Infrastructure Performance Management Software.
Auch im Jahre 2015 hält sich dieser Mythos hartnäckig. Jeder Netzwerker kennt die weit verbreitete Aussage: Der Netzwerkdurchsatz ist schlecht, wir brauchen mehr Bandbreite!
In einer kürzlich durchgeführten ![]() Performanceanalyse bei einem Kunden, durfte einer unserer Consultants wieder als Mythbuster auftreten, um die Mythen des IT-Alltags zu entzaubern.
Performanceanalyse bei einem Kunden, durfte einer unserer Consultants wieder als Mythbuster auftreten, um die Mythen des IT-Alltags zu entzaubern.
In diesem konkreten Fall gab es Beschwerden bei einer NAS-Synchronisierung über eine WAN-Strecke (300 Mbps Bandbreite und eine RTT um die 11 ms).
Die IO-Graphen in Wireshark sind ein effektives Hilfsmittel bei der Performanceanalyse. In der IO-Durchsatzgrafik ist erkennbar, dass für eine Session der maximale Durchsatz in Empfangsrichtung ca. 70 Mbps und für die Senderichtung ca. 12 Mbps beträgt.
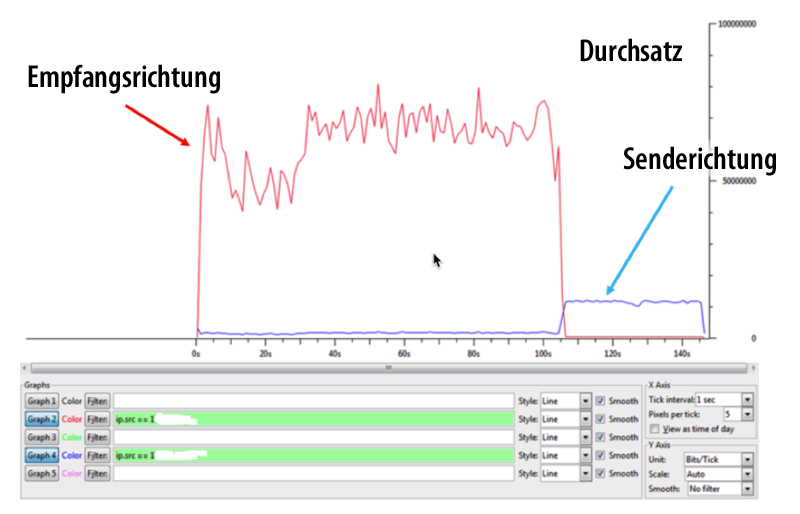
Mittels der IO-Window-Size-Grafik ist schnell der Grund für den Performanceengpass ersichtlich: Die Receive-Window-Size, also die maximale Menge an Puffer, die das NAS für eine Session/Socket/Verbindung zur Verfügung stellt, ist hier der Performancebremser.
Bei einer Window-Size von ca. 17kB beträgt der hier maximal erreichte Durchsatz in Senderichtung ca. 12 Mbps. Um das zu verifizieren, kann einfach mit dem Bandwidth-Delay-Produkt (BWDP) die max. mögliche Bandbreite berechnet werden:
Window-Size / RTT = 17kB / 11 ms<= 12,4 Mbps.
Fazit dieser Dienstleistung ist:
- Die Performancebremse ist die Receive-Window-Size von 17 kByte des NAS und nicht die verfügbare Bandbreite von 300 Mbps
- Eine Erhöhung der Bandbreite würde in diesem Fall nicht zu einem höheren Durchsatz führen. Eine (im Vergleich zum LAN) hohe Laufzeit, eine hohe Bandbreite, kombiniert mit einer kleinen Window-Size passen einfach nicht zusammen
- Lediglich die Erhöhung der Window-Size würde den Durchsatz erhöhen
- Neben der Bandbreite gibt es zwei wichtige Faktoren, die den maximal möglichen Durchsatz beeinflussen:
- Laufzeit
- Receive-Window-Size
- Sind diese beiden Faktoren bekannt, kann mit dem BWDP – ohne viel Aufwand – der maximal mögliche Durchsatz einer Session berechnet werden
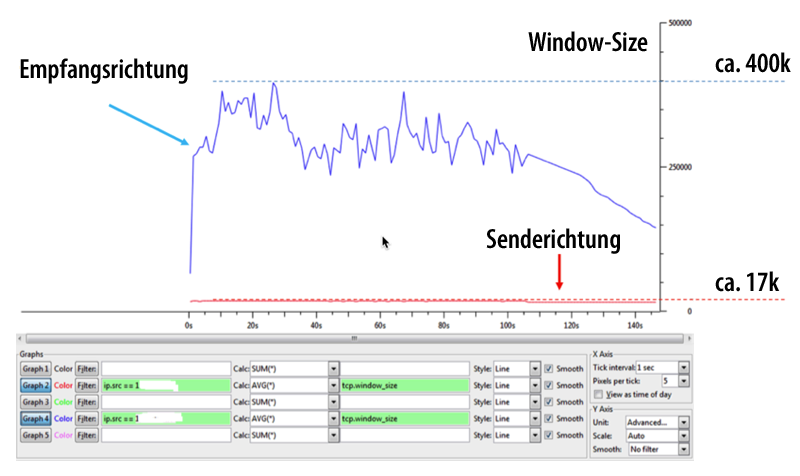
Mit diesen beiden Ergebnissen würde man bei den Mythbusters den Mythos als „busted“ deklarieren oder in unserer Sprache: Es ist weiterhin NICHT das Netzwerk!
Seit mit den Best Practice Ansätzen von ITIL das Servicedenken in der IT implementiert worden ist, haben sich viele Unternehmen schrittweise mit IT-Service-Management beschäftigt.
Viele unserer Kunden haben mit dem Incidents und Problem Management angefangen, Change und Release Management waren der nächste Schritt. In der dritten Phase folgte die Festlegung und Überwachung von Service Levels.
In dieser Phase lag der Fokus auf rein technisch orientierten KPIs, wie z.B. die Verfügbarkeit und Auslastung von Systemen & Applikationen, die Anzahl von Incidents und die Zeit der Fehlerbehebung.
Womit sich viele Unternehmen schwer tun, ist das Implementieren von End-User-Experience SLAs.
Bei diesen End-User-Experience SLAs stehen für Anwender relevante und nachvollziehbare Kennzahlen im Mittelpunkt.
Meist geht es darum, zu quantifizieren, wie viel Zeit bestimmte Business-kritische Aktivitäten benötigen, wie z.B. das Aufrufen einer Kundenakte, das Speichern einer Bestelländerung oder das Herunterladen von Dokumenten.
Viele Unternehmen hätten diese Kennzahlen zwar gerne aber nur wenige haben sie tatsächlich implementiert. Wie kann es sein, dass im Jahre 2015 nur eine geringe Anzahl von IT-Abteilungen Kennzahlen rund um die Anwenderzufriedenheit für die Kommunikation zwischen Business und IT nutzt?
Barrieren bei der Umsetzung
Wenn wir das Argument „kein Handlungsbedarf“ ausschließen, gibt es nach unserer Erfahrung folgende Hürden für End-User-Experience SLAs:
- Silo-Mentalität
Der Anwender ist nicht im Fokus, es wird nicht über die Grenzen der eigenen Abteilung oder gar die IT hinaus gedacht.
- Verliebt in Technik
Die IT sieht sich immer noch als Technologie-Lieferant, nicht als Erbringer eines Services.
- Ressourcen
Es fehlt an Personal und Zeit.
- Know-How
Es ist nicht genügend Wissen über methodische Ansätze und den Umgang mit passenden Tools vorhanden.
Bei den organisatorischen Herausforderungen (Punkt 1 und 2) können wir den Kunden nur eingeschränkt unterstützen. Für die Punkte 3 und 4 haben wir allerdings bewährte Methoden und Tools im Portfolio, um objektive Service Level Kennzahlen aus Anwendersicht erheben zu können.
Vor dem Einführen von SLAs für die Business-Aktivitäten der Endwender, ist es notwendig, zuerst die „normale“ Performance der Geschäftstransaktionen zu ermitteln.
Ein Ansatz, um diese Baseline-Informationen zu bekommen, ist ein synthetisches Monitoring.
Hierbei simuliert ein Skript periodisch Business-Aktivitäten und ermittelt dadurch die Transaktionszeiten. Allerdings liefert dieser Ansatz meist nur Antwortzeiten für lesende Geschäftstransaktionen, wie z.B. das Suchen einer Patientenakte. Ausführende Transaktionen, wie z.B. das Anlegen einer Bestellung, sind in der Praxis nur aufwendig zu realisieren.
Ein weiterer, gravierender Nachteil ist dabei auch das Fehlen von tatsächlichen End-User-Experience Messwerten. Diese sind elementar für die Fehlerbehebung individueller Performanceprobleme.
Ohne objektive und anwenderbezogene Leistungsinformationen auf Endgeräte- und Transaktionsebene sind Incidents zu Performance-Engpässe oft nur mühsam oder gar nicht zu analysieren und zu beheben.
Zwei wichtige Schritte
Zusammengefasst bedeutet das, dass folgende Funktionen benötigt werden:
- Baselining
Es müssen im ersten Schritt Business-Aktivitäten aus Anwendersicht für das Performance-Baselining gemessen werden. Dies ist die Basis für begründete Service-Levels.
- Festlegung der Service-Levels
Auf Basis der Baseline-Informationen werden die Service-Levels aller Business-Interakationen festgelegt. Nun werden Abweichungen vom Normalverhalten automatisch sichtbar gemacht.
Mit dem einzigartigen Business-Aktivitäten-Analytics Verfahren von ![]() Aternity können die Anwendungsperformance-Erfahrungen für jeden End-User überwacht werden.
Aternity können die Anwendungsperformance-Erfahrungen für jeden End-User überwacht werden.
Zusätzlich zu Applikationsantwortzeiten werden unter anderem weitere Performance-Metriken in Echtzeit gemessen:
- CPU-Auslastung des Desktops
- Speicherauslastung des Desktops
- Aktive Prozesse
- Anwendungsabstürze
Durch Korrelation dieser Metriken und Ereignisse zu den Anwendern, Anwendungen und IT-Komponenten ist schnell ersichtlich, welche Lokationen, Abteilungen, Server, Hardware-Konfigurationen und Business-Aktivitäten von den Performance-Engpässen betroffen sind.

In einem übergeordneten Analysebericht wird für jede Business-Aktivität der Durchschnittswert der Applikationsantwortzeit aus Anwendersicht (1) dargestellt. Dies ist die Grundlage für Service-Levels aus Anwendersicht.
Darauf basierend können Schwellwerte (2) für die End-User-Experience SLAs festgelegt werden. Jede Business-Interaktion der Endanwender wird mit den dazugehörigen SLA-Schwellwerten verglichen, sodass Unternehmen Applikationsperformanceprobleme proaktiv erkennen und lösen können. Ebenso ist die Häufigkeit der Schwellwertüberschreitungen (3) ersichtlich.
Für die Root-Cause-Analyse kann der Detailgrad schrittweise erhöht werden.
SLAs für in-house und outsourced Applikationen
Bemerkenswert an der End-User-Experience Monitoringlösung von Aternity ist, dass Unternehmen sie sehr flexibel einsetzen können. Sie können die Performance aus Endanwendersicht von Anwendungen messen, die im hauseigenen Rechenzentrum, von einem Cloud-Provider, einem SAAS-Anbieter oder einem Outsourcing-Dienstleister gehostet werden.
Mit der automatischen Problemerkennung kann schnell die Ursache erkannt und behoben werden.
Diskussionen ohne Grundlage zwischen den IT-Fachabteilungen entfallen und es gibt keine falschen Zuweisungen mehr - jedoch eine bessere End-User-Experience.
Eine der beliebtesten und wohl auch am weitesten verbreiteten Protokollanalyse Tools ist Wireshark. Leistungsstark und dazu auch noch kostenfrei! Eine Kombination, die nahezu perfekt scheint.
Für die bisher dominierenden 1G-Netze passte das meist auch sehr gut. Doch die Entwicklung ging in den letzten Jahren rasant voran, so dass wir heute an zentralen Punkten 10 oder gar 40G-Anbindungen vorfinden.
Doch wie messe ich hier nun mit meinem lieb gewonnenen Wireshark Analyzer?
Die Trace-Performance der Notebooks reicht nicht mehr aus und auch leistungsfähige Server-Hardware bietet nicht wirklich eine praktikable Lösung, wenn ich 100% der möglichen Last zur Fehleranalyse mitschneiden und später auswerten will.
Hier kommt häufig die kostspielige, proprietäre Messhardware namhafter Anbieter ins Spiel. Diese ist aber für viele Unternehmen meist nicht finanzierbar.
Um diese entstandene Lücke zu schließen empfehlen wir unseren Kunden die Lösung ![]() FlowMagic von der Firma Infinicore. Dabei handelt es sich um eine leistungsstarke Appliance, die in den letzten Jahren u.a. durch einen intensiven Austausch mit dem Hersteller und unseren technischen Consultants „deutsche“ Marktreife erlangt hat und durch ihr einmaliges Preis-/Leistungsverhältnis besticht.
FlowMagic von der Firma Infinicore. Dabei handelt es sich um eine leistungsstarke Appliance, die in den letzten Jahren u.a. durch einen intensiven Austausch mit dem Hersteller und unseren technischen Consultants „deutsche“ Marktreife erlangt hat und durch ihr einmaliges Preis-/Leistungsverhältnis besticht.
Überzeugen Sie sich gern einmal in Form einer kostenfreien ![]() Teststellung davon.
Teststellung davon.
Das nun schon dritte Gerät der GeNiJack-Reihe ist seit Anfang des Jahres bei uns erhältlich - der GeNiJack 301. Neben dem neuen Aussehen hat sich auch innerlich einiges getan. Aber zunächst ein wenig über das Testmodell vor dem ![]() GeNiJack 301.
GeNiJack 301.
Hauptaugenmerk lag bei der Auswahl eines neuen Geräts auf der Netzwerkperformance. Der neue GeNiJack sollte auch auf Gigabitstrecken genaue Performancewerte ermitteln können und noch genügend Leistung haben, um nebenbei einen Paketmitschnitt auszuführen.
Zunächst fiel ein Gerät mit einem Cortex A9 Quad-Core und zwei Gigabit-Ethernet-(GbE) Ports auf, welches ich auch kurz darauf auf meinem Tisch hatte. Leider wurden bei Messungen mit Laborbedingungen nur etwa 250 Mbit/s auf dem ersten und 500 Mbit/s auf dem zweiten GbE-Port festgestellt. Eingesetzt wurde IxChariot 7.30 und als Referenz Iperf. Das schlechte Abschneiden auf dem ersten Port ließ sich auf die Anbindung über USB 2.0 auf der Platine zurückführen. Der zweite Port ist zwar über eine PCI-Lane angebunden, jedoch haben wohl Treiberprobleme zu dem schlechten Durchsatz geführt. Leider konnte hier keine Lösung gefunden werden.
Nach weiterer Recherche tat sich eine stärkere Hardware auf: Verbaut ist ein Intel Atom E3845 Quad-Core und wieder zwei GbE-Ports, zusätzlich sind drei USB 3.0 Ports vorhanden.
Nach den ersten Tests des Geräts war schnell klar, dass die gesuchte Leistung vorhanden ist. Ein TCP Duplex Test wurde mit ca. 940 MBit/s pro Richtung durchgeführt. Auch bei einem TCP Duplex Test über beide GbE-Ports gab es keine Einbrüche. Es wurden also vier Pairs mit einer Gesamtbandreite von ca. 3.8 GBit/s problemlos gemessen.

Durchsatztest vom GeNiJack 301
Nach kleinen Verfeinerungen am System (Debian 7) und dem Einspielen der ![]() GeNiEnd2End Software, sowie dem vom GeNiJack bekannten GeNiJackManager, konnten erste, zufriedenstellende Kundentests durchgeführt werden.
GeNiEnd2End Software, sowie dem vom GeNiJack bekannten GeNiJackManager, konnten erste, zufriedenstellende Kundentests durchgeführt werden.
Der GeNiJack 301 steht nun mit 4 GByte Arbeitsspeicher und 500 GB Festplatte seit Januar bei uns zur Verfügung.
Diese Woche gab es zum o.g. Thema wieder eine intensive Diskussion in einer meiner LinkedIn Gruppen. Es erinnerte mich an die Zeit, in der Token Ring Befürworter sich mit den Ethernet Gegnern darüber stritten, wer die bessere Technologie habe. Oder wer kennt noch den Formatkrieg bei den Videorekordern: VHS vs. Betamax vs. Video 2000?
Tja, was ist jetzt besser: Ein End-User-Experience Monitoring auf Basis von Agenten oder mit Appliances? Wie immer gibt es Pro und Cons bei beiden Ansätzen. Was ich aber bei diesen Diskussionen immer vermisse, ist, dass der Reifegrad der IT-Organisation, resp. das Know-How, bei der Auswahl des Monitoringansatzes vergessen wird.?
Vielleicht erinnern Sie sich noch an das Gartner IT Infrastructure and Operations Model. Hier wird sehr übersichtlich dargestellt, dass neben der Technologie auch die Entwicklungsstufe der Prozesse und der IT-Mitarbeiter eine wichtige Rolle spielen; oder wie wir sagen: Die richtige Technologie, mit den richtigen Informationen für die richtige Person zur richtigen Zeit.
Deshalb führen wir in unserem Produktportfolio sowohl agentenbasierende Systeme, wie z.B. ![]() GeNiEnd2End oder, jetzt ganz neu,
GeNiEnd2End oder, jetzt ganz neu, ![]() Aternity als auch agentenlose Systeme, wie z.B.
Aternity als auch agentenlose Systeme, wie z.B. ![]() SecurActive APS oder
SecurActive APS oder ![]() Fluke Networks TruView.
Fluke Networks TruView.
Bei einigen Projekten haben wir sogar beide Ansätze miteinander gemischt. Wir kennen uns hier aus, da wir täglich bei unseren Troubleshooting-Dienstleistungen genau die Tools einsetzen, die am schnellsten die Verursacher der Performanceprobleme aufdecken.
Und wer ist jetzt technisch besser? Wie auch in den Zeiten des Formatkrieges bei den Videorekordern, entscheiden andere Dinge über Wohl und Wehe einer Technologie.
Immer wieder erlebe ich die Situation, dass vom Kunden, nach der Vorstellung einer für ihn sowohl technisch als auch preislich passenden Lösung, die Frage nach Referenzkunden kommt.
Dies ist absolut nachvollziehbar, denn es geht doch nichts über „Gleichgesinnte“, die mit ihren guten Erfahrungen im Umgang mit dem Produkt Rede und Antwort stehen.
Enttäuschung kommt dann gern mal auf, wenn es „nur“ einen offiziellen Referenzkunden gibt und dieser dann zusätzlich noch am anderen Ende der Republik beheimatet ist.
Da wird dann gern mal nachgehakt: „Haben Sie denn keinen weiteren Referenzkunden?“ Und damit verbunden kleine Zweifel ausgedrückt, ob das vorgestellte Produkt die richtige Wahl ist.
Meine Antwort ist dann wahrheitsgemäß, wie auch ernüchternd: „Nein, wir haben viele zufriedene Kunden, die gerade diese Lösung einsetzen, die aber nicht als Referenzkunde genannt werden wollen.“
Die Ursache dafür ergibt sich dann aus meiner nachfolgenden Frage an den Kunden: „Könnten wir SIE als Referenzkunden aufführen, wenn sie das Preis-/Leistungsverhältnis überzeugt und sie sich für einen Kauf entscheiden sollten?“
Meist folgt dann eine kleine Pause und der Kunde beginnt seine Antwort mit: „Von mir aus gern, aber bei uns ist das nicht so einfach...“ oder schlicht „Das machen wir grundsätzlich nicht.“
Zum Glück gibt es dann doch Kunden, die so überzeugt von unserer Lösung sind, dass sie den meist steinigen und langwierigen Weg in ihrem Unternehmen gehen und die Genehmigung erhalten, um als Referenzkunde zur Verfügung zu stehen.
In diesem Zusammenhang sind über die Jahre einige interessante ![]() Projektberichte entstanden, die wir auf unserer Webseite zum Download zur Verfügung stellen.
Projektberichte entstanden, die wir auf unserer Webseite zum Download zur Verfügung stellen.
Grundsätzlich ist meiner Ansicht nach eine ![]() Teststellung des Produktes im Hause des Kunden viel aussagefähiger für ihn in Punkto Nutzen und Bedienbarkeit, als ein Referenzkunde, von dem man nicht weiß, wie viel Aufwand getrieben werden musste, um die Lösung in einen vorzeigbaren Zustand zu bringen.
Teststellung des Produktes im Hause des Kunden viel aussagefähiger für ihn in Punkto Nutzen und Bedienbarkeit, als ein Referenzkunde, von dem man nicht weiß, wie viel Aufwand getrieben werden musste, um die Lösung in einen vorzeigbaren Zustand zu bringen.
Langsam kommt der 802.11ac WLAN-Standard in Schwung und immer mehr Kunden wollen eine 802.11ac konforme Ausleuchtung durchführen. Somit ist es an der Zeit, das Thema mal genauer unter die Lupe zu nehmen und ein paar Hinweise zu geben.
![]() AirMagnet Survey unterstützt folgende 802.11ac WLAN-Adapter:
AirMagnet Survey unterstützt folgende 802.11ac WLAN-Adapter:
 Netgear® A6200 WiFi USB Adapter – 802.11ac Dual Band
Netgear® A6200 WiFi USB Adapter – 802.11ac Dual Band- Netgear® A6210 WiFi USB Adapter – 802.11ac Dual Band
- Intel® Dual Band Wireless-AC 7260 (Intern)
- Intel® Dual Band Wireless-AC 7265 (Intern)
Verwenden Sie bei dem Netgear A6200 WLAN-Adapter den aktuellsten Beta-Treiber, damit Sie auch alle Kanäle in Deutschland benutzen können. Dieser funktioniert auch unter Windows 7 (Treiber unterstützt DFS) : ![]() Link zur Netgear Seite
Link zur Netgear Seite
Einschränkungen und Hinweise:
Es kann nur ein 802.11ac Adapter gleichzeitig genutzt werden. Alle Unterstützten 802.11ac Adapter können aktuell keine Noise Werte aufzeichnen!
Windows XP wird in Zusammenhang mit 802.11ac Adaptern nicht unterstützt.
Verfügbare Adapter unterstützen WLAN-Verbindungsgeschwindigkeiten bis maximal 867Mbits.
Wenn ein 802.11ac Adapter genutzt wird, sind ein paar Funktionen nicht nutzbar:
- VoFi Survey, Roaming Control für Aktive Surveys / Aktive IPERF Surveys
- Anzeige des aktuell gescannten Kanals
Empfohlene AP-Einstellungen bei Active Surveys in Zusammenhang mit AP on a Stick:
- AP konfiguriert als DHCP Server und Gateway. WLAN Adapter konfiguriert auf DHCP
- AP konfiguriert als DHCP Server und Gateway nicht konfiguriert. WLAN-Adapter konfiguriert auf DHCP
- AP konfiguriert nicht als DHCP Server, statische IP Adresse, Gateway nicht konfiguriert. WLAN-Adapter konfiguriert mit statischer IP Adresse in dem selben Bereich wie der AP
Hinweise zu den Systemanforderungen: ![]() AirMagnet Systemanforderungen
AirMagnet Systemanforderungen

Ich nutze ihn sehr gerne für die Analyse von Problemen jeglicher Art und ich gebe das Wissen ausgesprochen gerne in unseren ![]() Wireshark Schulungen weiter. Aber wie jedes Produkt hat auch Wireshark Grenzen. An diese bin ich in einer der jüngsten
Wireshark Schulungen weiter. Aber wie jedes Produkt hat auch Wireshark Grenzen. An diese bin ich in einer der jüngsten ![]() Analysen gestoßen. Ein Kunde brauchte eine Auswertung zur Belastung einer WAN-Leitung für ausgewählte Citrix-Transaktionen, um ermitteln zu können, wie viel Last bestimmte Transaktionen tatsächlich erzeugen und wie hoch dann die Last bei einer bestimmten Anzahl an Anwendern ist.
Analysen gestoßen. Ein Kunde brauchte eine Auswertung zur Belastung einer WAN-Leitung für ausgewählte Citrix-Transaktionen, um ermitteln zu können, wie viel Last bestimmte Transaktionen tatsächlich erzeugen und wie hoch dann die Last bei einer bestimmten Anzahl an Anwendern ist.
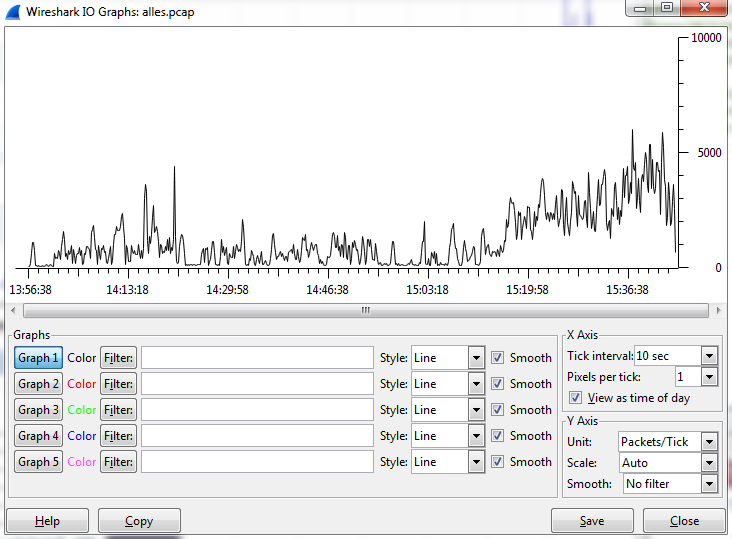
Wireshark I/O Graph
Nun, Wireshark kann hier nur sehr begrenzt mit dem I/O Graphen punkten und speziell bei dieser Aufgabenstellung ist er das falsche Werkzeug. Somit habe ich ![]() WildPackets OmniPeak getestet, der in dieser Disziplin mit deutlich mehr Informationen daherkommt und auch eine sehr hohe Messauflösung bereitstellt. Die zusätzlichen Informationen wie Top Talker, Listener und Applikationen waren mehr als hilfreich.
WildPackets OmniPeak getestet, der in dieser Disziplin mit deutlich mehr Informationen daherkommt und auch eine sehr hohe Messauflösung bereitstellt. Die zusätzlichen Informationen wie Top Talker, Listener und Applikationen waren mehr als hilfreich.
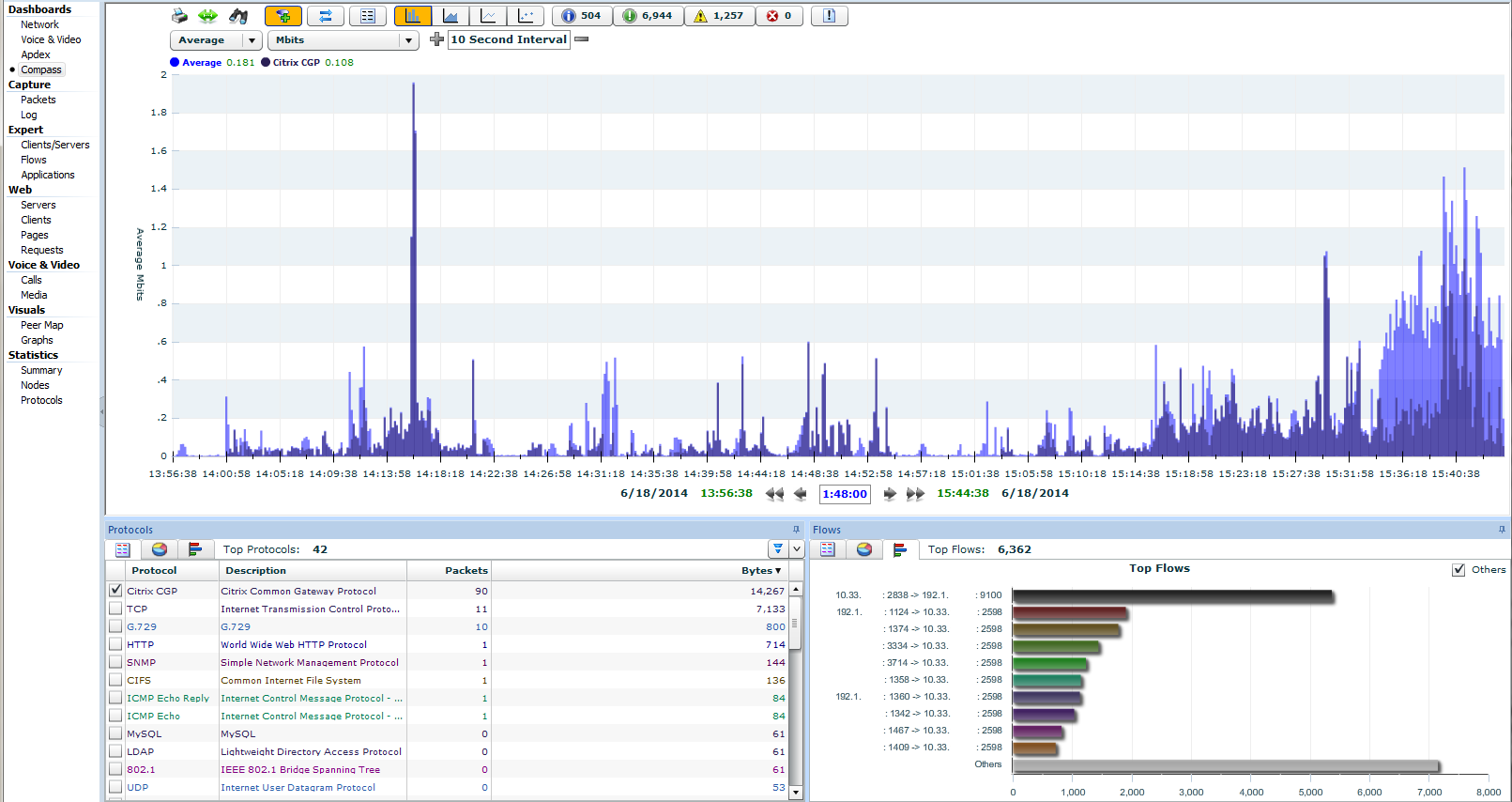
Wildpackets OmniPeek Compass
Dadurch konnte ich die Analyse schneller und mit einer höheren Informationsdichte als geplant erstellen. Ich bin mir sicher, dass OmniPeak noch viel mehr kann, ich bin offen für neues, wie auch NETCOR. Wir schauen immer über den Tellerrand, um die beste Lösungen für unsere Kunden zu suchen, zu testen, in der echten Praxis zu erproben und auch empfehlen zu können.
Somit bieten wir immer die richtige Lösung für die Anforderungen unserer Kunden. Und meinen Wireshark, den werde ich immer lieben, er ist in vielen Bereichen einfach das richtige Werkzeug.
Analyse von Datenpaketen mit Wireshark & Co. gehört zu der Königsdisziplin bei den Netzwerkspezialisten. Gerade bei Netzwerkfehlern und Performanceproblemen ist es häufig das letzte Mittel der Fehleranalyse. Oder wie der Netzwerker sagt: Die Wahrheit steckt in den Datenpaketen.
Für solche Fälle ist die Open-Source Analysesoftware Wireshark aufgrund der vielseitigen Einsatzmöglichkeiten das bevorzugte Tool. Allerdings - wie ist das in 10G Netzwerken mit hoher Netzwerklast und bei sporadischen Problemen? Eine Lösungsmöglichkeit wäre hier eine Streaming-to-Disk Appliance. Meistens übersteigen die Kosten und die Komplexität von 10G Datenrekordern die Anforderungen der Anwender und die einzige Alternative ist eine Capture-Appliance selber zu bauen. Allerdings ist der Eigenbau eines Hochleistungsdatenrekorders nicht jedermanns Sache.
Abhilfe schafft hier die FlowMagic Streaming-to-Disk Appliance von ![]() InfiniCore. Nach dem Motto „do more with less“ liefert InfiniCore mit FlowMagic einen hochperformanten, modularen Netzwerkdatenrekorder inkl. eines skalierbaren Speicherkonzepts mit einem ausgezeichneten Preis-/Leistungsverhältnis. Die intuitive, web-basierende Benutzeroberfläche unterstützt den Netzwerkspezialisten bei der forensischen Analyse von Performanceanomalien.
InfiniCore. Nach dem Motto „do more with less“ liefert InfiniCore mit FlowMagic einen hochperformanten, modularen Netzwerkdatenrekorder inkl. eines skalierbaren Speicherkonzepts mit einem ausgezeichneten Preis-/Leistungsverhältnis. Die intuitive, web-basierende Benutzeroberfläche unterstützt den Netzwerkspezialisten bei der forensischen Analyse von Performanceanomalien.
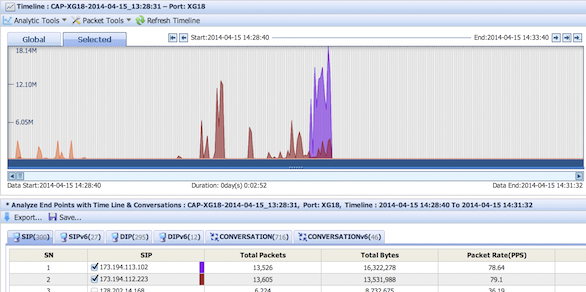
Vorselektion (z.B. nach Zeitraum, IP-Adressen) der Datenpakete für den anschließenden Datenexport in eine Pcap-Datei
Die nachträgliche Detailanalyse erfolgt dann mit dem integrierten WireShark Packet Viewer. Alternativ können die Datenpakete für eine Analyse exportiert werden.
Für eine bessere Handhabung können die Datenpaketen nach Kriterien, wie z.B. Zeitraum oder IP-Adressen, mittels des integrierten Analytic Tools vorselektiert werden.
FlowMagic, ist es Magie? Finden Sie es raus indem Sie FlowMagic testen.
Seit GeNiEnd2End 4.6 wird nun Python als Skriptsprache für das Application-Testing unterstützt. Python ist eine syntaktisch einfach zu erlernende, aber mächtige Programmiersprache. Warum es dennoch "Light" ist und was Sie alles damit machen können, werde ich Ihnen jetzt erklären.
Einer der Hauptpunkte der für Application Light, also Python als Programmiersprache, spricht, ist wohl, dass diese Skripte meist ohne weitere Anpassungen sowohl auf Windows PC als auch auf unseren hauseigenen GeNiJacks laufen. Um dies zu realisieren, wird unter Windows ein eigens mitgelieferter Python Interpreter verwendet. Auf den GeNiJacks ist dieser sogar schon vorinstalliert und wird durch die Update-Funktionalität der GeNiJacks immer aktuell gehalten. Dadurch, dass Python "interpretiert" wird, müssen die Skripte auch nicht für das jeweilige System kompiliert werden, sondern können einfach über den Interpreter ausgeführt werden.
Code für einen DNS Resolve Test
AutoIT hat eine, für uns, ungeschlagene Mechanik, um grafische Benutzeroberflächen (GUI)-Abläufe zu automatisieren. Wenn es jedoch darum geht außerhalb einer GUI zu agieren, ist Python eine gute Wahl. Dies kommt auch durch die sehr aktive Python-Community, die viele ihrer Skripte und Bibliotheken freigibt und für andere verfügbar macht. Das "DNS resolve" Skript, welches mit GeNiEnd2End 4.6 ausgeliefert wird, basiert auf einer solchen freien Bibliothek und ist in etwas mehr als zwanzig Zeilen Quellcode realisiert worden.
In dem "traceroute" Skript, welches auch mit GeNiEnd2End 4.6 mitgeliefert wird, wird hingegen auf das Betriebssystem eigene Traceroute Programm (tracert) zugegriffen. So lässt sich Programmierarbeit durch 3rd Party Anwendungen sparen, lediglich die Rückgabe des Programms muss ausgewertet werden.
Mit Application Light, lassen sich also in kürzester Zeit Testszenarien erstellen.
Messergebnisse in GeNiEnd2End Application
Dinge wie Website-Tests lassen sich nicht nur mit ![]() GeNiEnd2End Application sondern auch mit Application Light erstellen. Hier müssen aber Abstriche gemacht werden.
GeNiEnd2End Application sondern auch mit Application Light erstellen. Hier müssen aber Abstriche gemacht werden.
Zum einen wird bei Website Tests nur die Seite heruntergeladen und nicht wie bei GeNiEnd2End Application in einem Browser geöffnet. Dies hat zur Folge, dass zum Beispiel clientseitige Ereignisse, wie Javascript-Funktionen oder CSS-Renderzeiten nicht zum Tragen kommen und nicht in Gesamtzeit einfließen. Außerdem sind CNS-Zeiten für Application Light nicht verfügbar.
Wenn nun also die nicht ganz so aussagekräftigen "Messwerte", in klare und zuverlässige Messwerte verwandelt werden können und dabei die Messdaten auch noch aufgeteilt werden können in "Client / Netzwerk / Server" ist das doch fantastisch, oder?
Wir haben schon viele Jahre Erfahrungen mit dem Thema Applikationsperformance und haben nicht nur bei Kunden eben die oben genannten Problembeschreibungen erhalten, sondern auch schon bei uns selbst. Aus diesem Grund überwachen wir selbst auch seit längerem die Applikationsperformance von z.B. Lotus Notes (IBM Notes) und unsere darauf aufbauenden Datenbanken.
Anhand dessen möchte Ich Ihnen heute zeigen, wie Sie zu Messdaten kommen können, die Ihnen dabei helfen die Probleme aufzuzeigen und einzugrenzen.
Jede Messung, die den gleichen Ablauf wie ein Anwender durchführen soll, beginnt mit einer Klickstrecke:
Jetzt benötigen wir einen ![]() GeNiEnd2End Application Server und einen Client PC. Der Client PC sollte dieselbe Hardware / Software / Netzwerkanbindung und Beschränkungen wie andere Client PC haben.
GeNiEnd2End Application Server und einen Client PC. Der Client PC sollte dieselbe Hardware / Software / Netzwerkanbindung und Beschränkungen wie andere Client PC haben.
Nun wird der ganze Ablauf der Klickstrecke mithilfe eines Skriptes (AutoIT oder Python) auf dem Client PC nachgebildet und dann in GeNiEnd2End als Skripting Test hochgeladen. Dieser Test wird dann in einem konfigurierten Intervall durchgeführt und die Messdaten werden mit Hilfe des GeNi Agenten, der auf dem Client PC installiert ist, an den Server gesendet.
![]() Konfiguration des Scripts in GeNiEnd2End
Konfiguration des Scripts in GeNiEnd2End
![]() Ablauf des Scripts als animiertes Gif
Ablauf des Scripts als animiertes Gif
Sobald das Script erstellt (in diesem Fall ca. 4-6 Std. mit Tests) und in GeNiEnd2End eingeplant wurde, werden die Messdaten aufgezeichnet und zur Analyse bereitgestellt. Sie können auch Schwellwerte zu den einzelnen Transaktionen hinterlegen, so dass Sie dann einen Alarm bekommen, wenn dieser über- bzw. unterschritten wurde.

Beispiel: Unterschied nach unseren Änderungen und 1 Jahres - Übersicht der Messdaten
| Legende: Blau ist die Clientzeit / Gelb die Netzwerkzeit / Rot die Serverzeit |
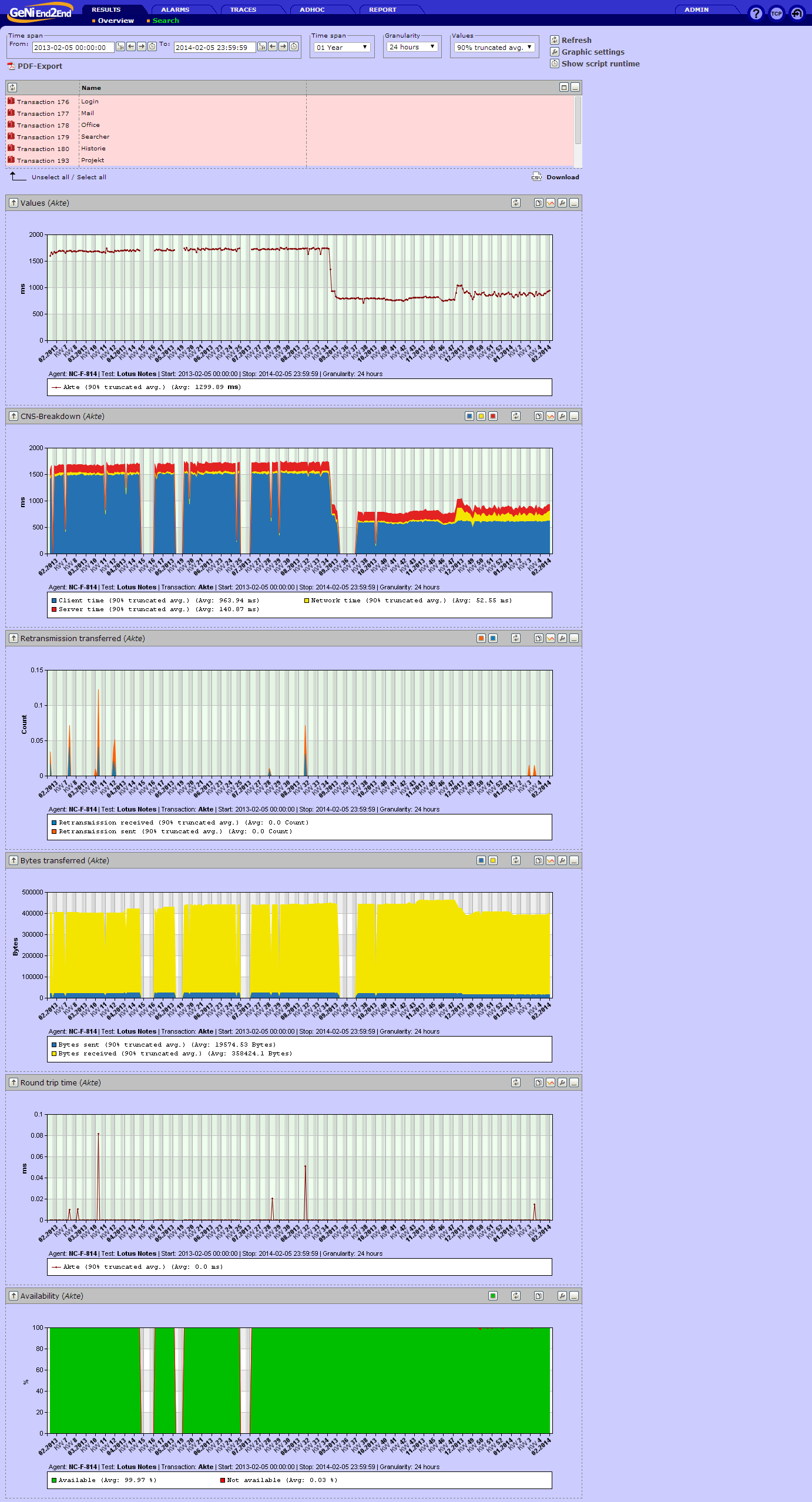 |
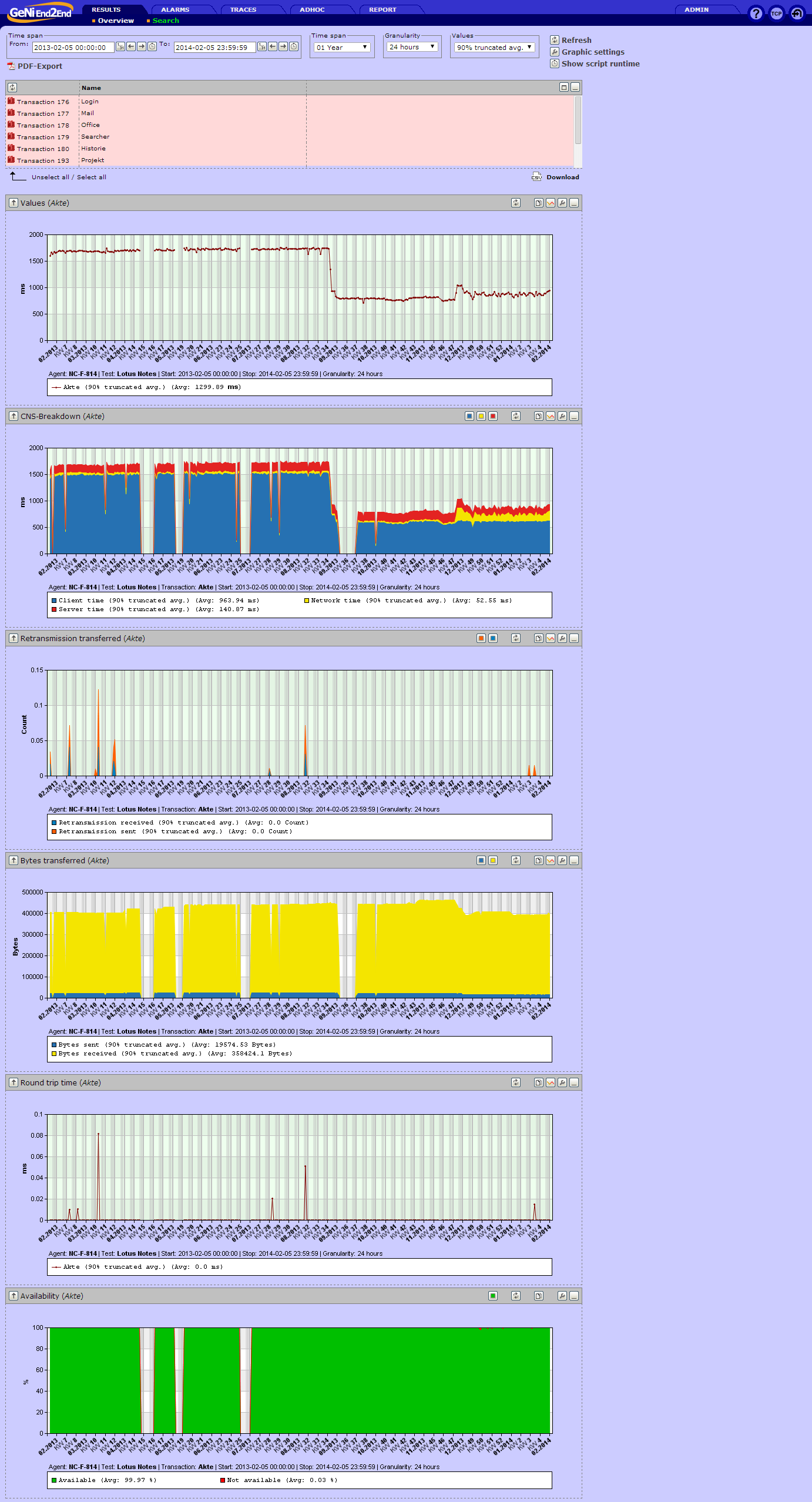 |
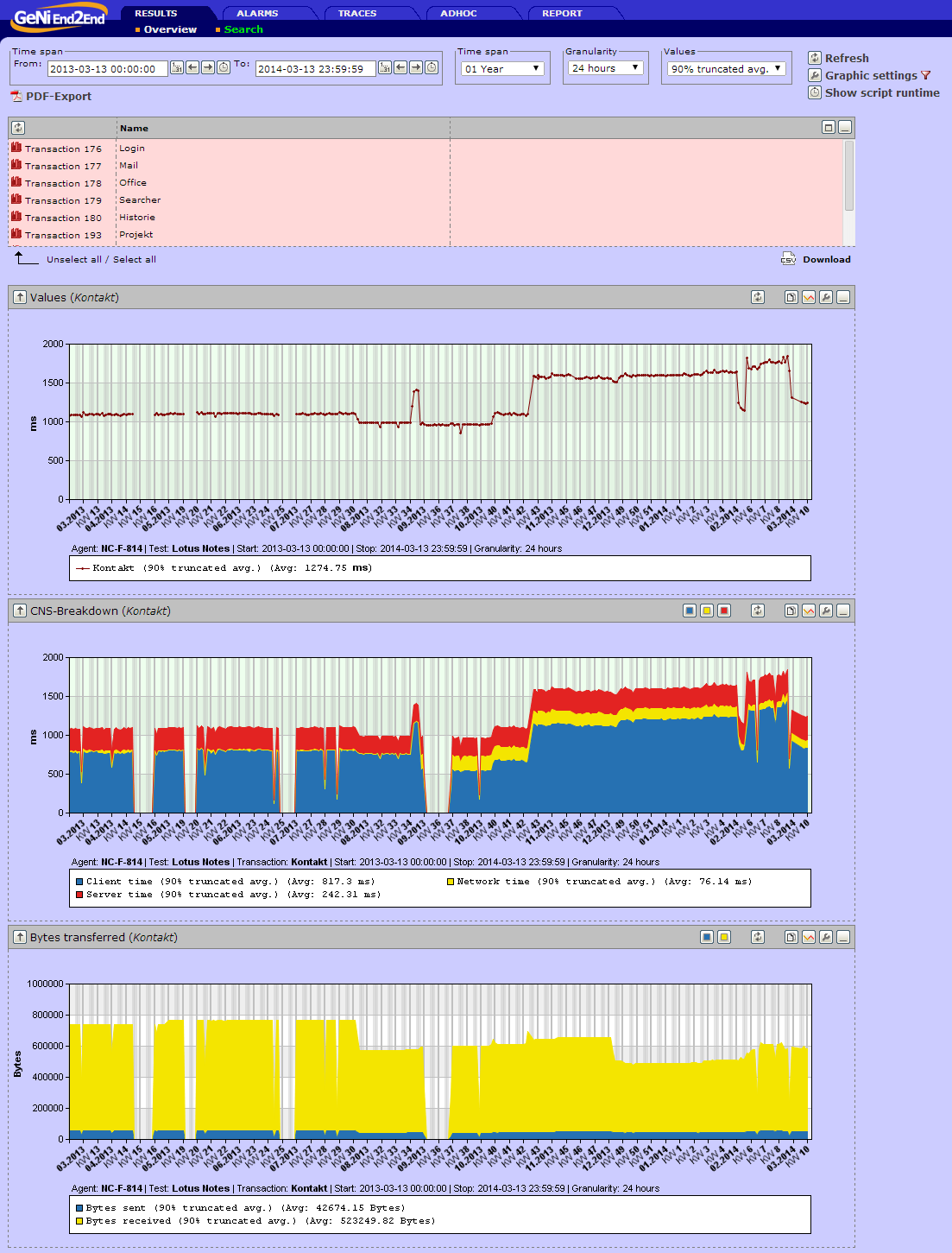 |
| |
Wie man sieht, haben wir einige Änderungen durchgeführt, um die Zeiten zu verringern. Die Änderungen haben wir auch mit demselben Script in einer Testdatenbank zuvor erarbeitet bzw. überprüft.
Dass der Weg keine Einbahnstraße in Richtung "schneller" ist, sieht man an der Kontakt-Transaktion: Allerdings sind dort auch viele neue Funktionen eingeflossen.
(Akte von 1,6 Sek auf unter 1,0 Sek reduziert, Searcher Open von 6,4 Sek auf unter 4 Sekunden, Kontakt von 1 Sek auf 1,5 Sekunden erhöht und dann wieder auf 1,2 verringert)
Leider können wir die Netzwerkzeit bei der Searcher Open Transaktion nicht beeinflussen, da diese durch die Funktion im IBM Notes Client entsteht, aber wir konnten den Client zumindest so konfigurieren, dass das Öffnen des Searchers parallel weiter läuft und der Anwender währenddessen schon arbeiten kann.
Der Pflegeaufwand für solch ein Script hängt natürlich davon ab, wie sehr sich Ihre Applikation ändert, bzw. ob viele Probleme auftreten (Fehlermeldungen usw.). Bei diesem Script waren es im letzten Jahr vielleicht 4-8 Stunden Pflegeaufwand, da wir sehr viel am Aussehen und am Umgang mit unseren Datenbanken geändert haben.
Von IBM Notes über Webseiten zu Citrix Applikationen, alles kann zur Erhebung von Messdaten genutzt werden. Fragen Sie uns doch einfach, wie wir Ihnen dabei behilflich sein können.
Natürlich können wir das Erstellen der Messungen / Analysieren oder Schulen, wie man Skripte erstellt, für Sie übernehmen:
In diesem Blog möchte ich einen Blick auf Paketverluste werfen, die üblicherweise Netzwerkprobleme bei der Performance der Applikationen darstellen. Warum ist also der Paketverlust solch ein Performance-Killer für die Applikation? Dies beruht vor allem auf der Art, wie TCP diese Paketverluste behandelt. Bestätigt innerhalb einer bestimmten Zeit (TCP-Timeout) der Empfänger die gesendeten Datenpakete nicht, so werden diese erneut vom Sender verschickt. Durch diese Timeouts können schwerwiegende Verzögerungen auftreten, da der Timeout-Wert sich bei jeder neuen Paketwiederholung verdoppelt.
Wir haben herausgefunden, dass viele IT-Administratoren der Meinung sind, ein Paketverlust-Wert von 1-2% sei sehr gering und sollte kaum Auswirkungen auf die Anwendungsperformance haben.
Leider hat bereits ein geringer Wert einen hohen Einfluss auf den TCP-Durchsatz, was wiederum die Applikationsperformance beeinträchtigt. Wir empfehlen bei einem Paketverlust-Wert von über 0,01% die Ursache zu ermitteln.
Der Aufwand, Paketverluste mit ![]() GeNiEnd2End Network zu bestimmen, ist ein Klacks. Sie können entweder den kostenlosen Software-Endpunkt auf bereits vorhandene PC / Server installieren oder positionieren die kostengünstigen
GeNiEnd2End Network zu bestimmen, ist ein Klacks. Sie können entweder den kostenlosen Software-Endpunkt auf bereits vorhandene PC / Server installieren oder positionieren die kostengünstigen ![]() GeNiJacks an die Abgrenzungspunkte.
GeNiJacks an die Abgrenzungspunkte.
GeNiEnd2End Network berichtet neben Paketverlust auch über One-Way-Latency, Jitter und andere wichtige Parameter der Netzwerkqualität.
GeNiEnd2End Network ist die perfekte Ergänzung für bereits bestehende, netzwerkbasierte APM-Lösungen wie SuperAgent von CA, Application Xpert von Opnet oder TruView von Fluke Networks. Es vereinfacht die Diagnose von Netzwerk Performance Problemen erheblich.
Mit GeNiEnd2End ist es eine Kleinigkeit zu beweisen, dass es "nicht das Netzwerk“ ist.
Lassen Sie mich also erklären, warum eine aktive endpunktbasierte Lösung wie GeNiEnd2End Network der beste „Gefährte“ für eine netzwerkbasierte APM-Lösung ist:
Innerhalb einer netzwerkbasierten APM Lösung wird der Paketverlust mit Hilfe von den Metriken Client- und Server-Retransmissions dargestellt. Jedoch kann durch diese beiden Metriken der Verursacher (Netzwerk, Client oder Server) und die Richtung (rückwärts, vorwärts) der Paketverluste nicht eindeutig bestimmt werden.
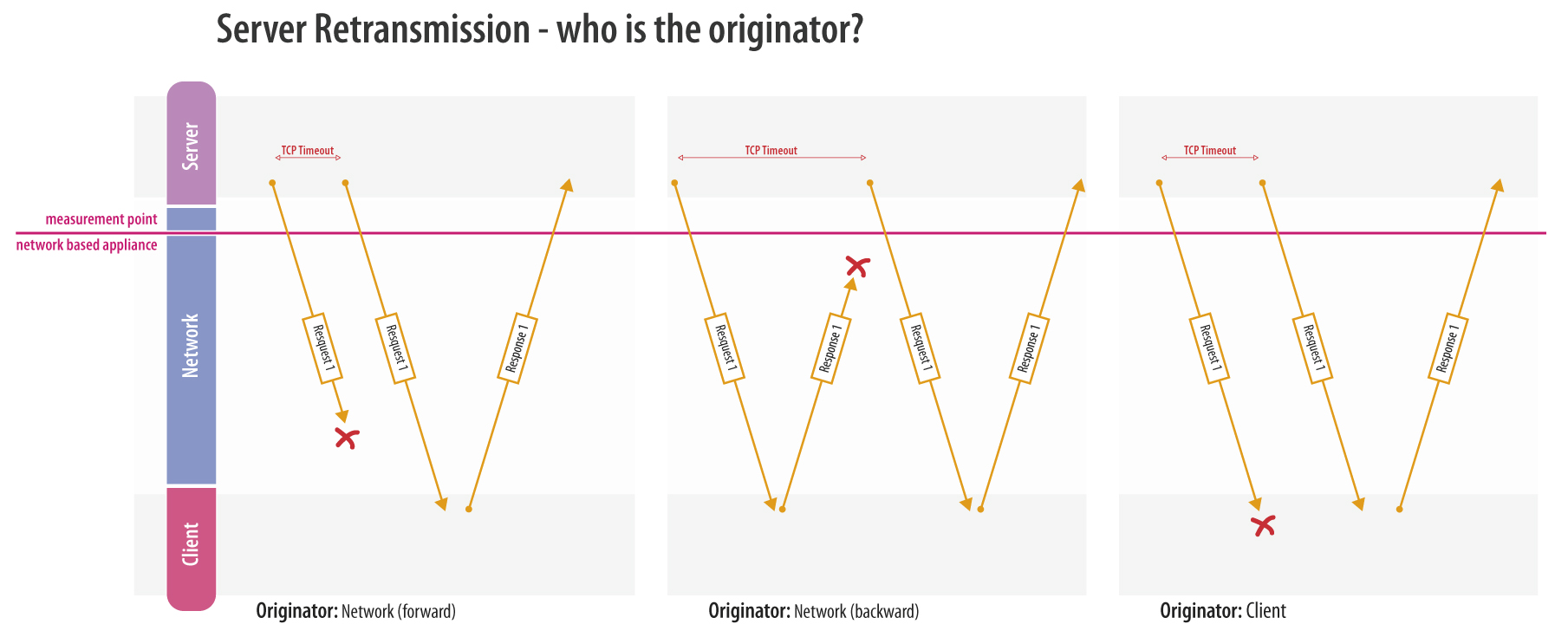
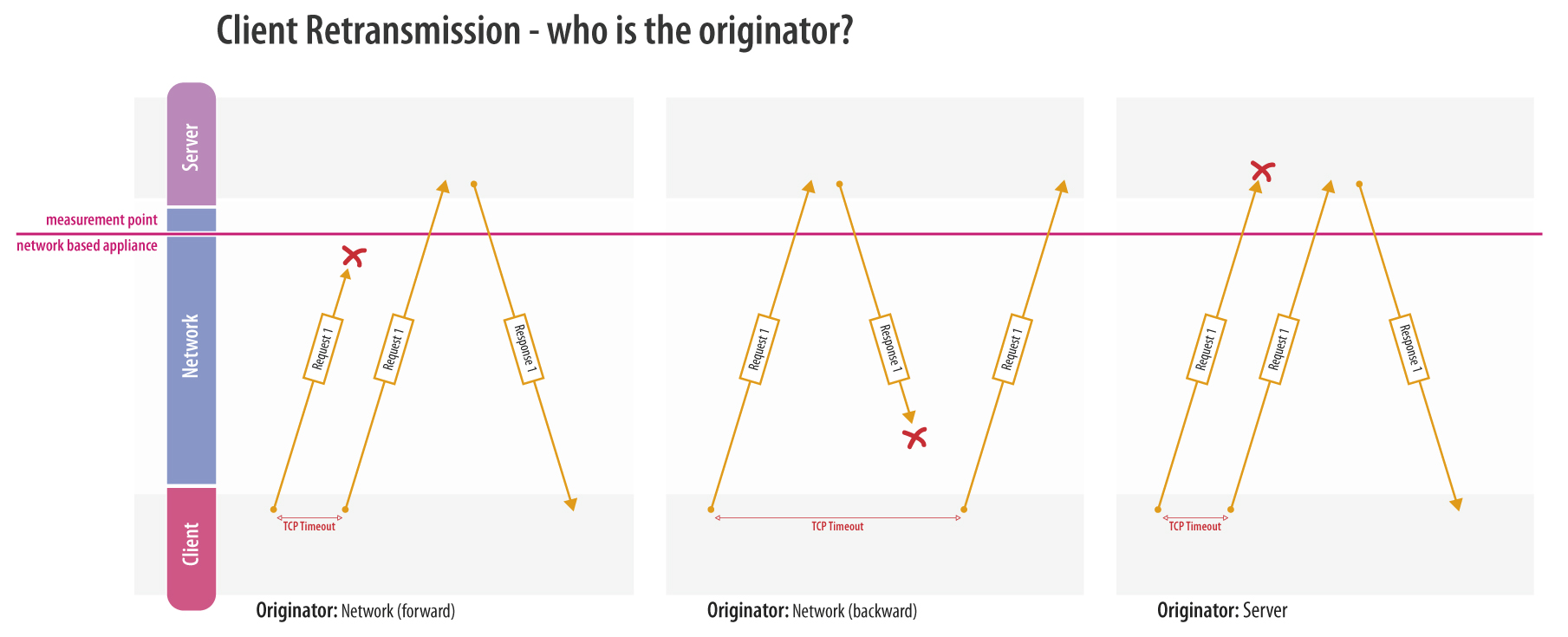
Bitte werfen Sie einen Blick auf die o.a. Bounce-Diagramme.
Mit GeNiEnd2End Network können Sie jedoch schnell bestimmen, ob das Netz die Paketverluste verursacht oder nicht.
Das Erfassen der Paketverluste ist für das Netzwerk-Team hinsichtlich der Diagnose von Performanceproblemen der Applikation und deren Ursache im Netzwerk der erste Schritt.
GeNiEnd2End Network rationalisiert den Workflow der Fehlerbehebung und ermöglicht es dem Netzwerk-Team, den Problembereich zu isolieren.
GeNiEnd2End Network – the real Troubleshooting tool for the Network Engineer!
Ziel eines Kundenauftrages war es, eine Matrix zu erstellen, die die Erreichbarkeit von einer beliebigen Anzahl von Lokationen weltweit abbilden kann.
Da der Kunde schon die Lösung ![]() GeNiEnd2End, die im Hause NETCOR entwickelt wird, verwendet, können die Messwerte aus der offengelegten Datenbank hierfür genutzt werden. GeNiEnd2End misst die Verfügbarkeit beliebiger Lokationen, speichert die Erreichbarkeit 24/7 in einer Datenbank und stellt diese in einer 24-Stunden-Übersicht dar.
GeNiEnd2End, die im Hause NETCOR entwickelt wird, verwendet, können die Messwerte aus der offengelegten Datenbank hierfür genutzt werden. GeNiEnd2End misst die Verfügbarkeit beliebiger Lokationen, speichert die Erreichbarkeit 24/7 in einer Datenbank und stellt diese in einer 24-Stunden-Übersicht dar.

(Farbige Markierungen deuten auf eine schlechte Verfügbarkeit hin)
Ziel war es, diese Daten in einer Matrix darzustellen, welche die aktuelle Verfügbarkeit pro Standort farbig darstellen soll.
Die Erweiterung "GeNiEnd2End Matrix" ermittelt einen Durchschnittswert des aktuellen Tages und vergleicht diesen mit dem aktuell gemessenen Wert. Kommt es zu Verschlechterungen zwischen dem Durchschnittswert und dem aktuellen Wert, so wird diese Lokation in der Matrix farbig hervorgehoben. Die gemessene Verschlechterung ist prozentual einstellbar und kann beispielsweise bei einem negativem Ergebnis von 5% gelb oder von 10% orangefarben dargestellt werden.
Die Ansicht zeigt alle Verfügbarkeiten auf einen Blick an, der Kunde kann somit schneller und effektiver arbeiten.
Der nächste WLAN-Standard steht vor der Tür und soll 2014 verabschiedet werden.
Dieser neue Standard heißt 802.11ac und verspricht unter anderem:
- Höhere Geschwindigkeiten (Durchsatz + Kapazität)
- Geringere Latenzzeit
Die ersten Geräte sind schon länger im Handel erhältlich, ![]() AirMagnet WiFi Analyzer unterstützt bereits das Dekodieren von 802.11ac Paketen und
AirMagnet WiFi Analyzer unterstützt bereits das Dekodieren von 802.11ac Paketen und ![]() AirMagnet Survey kann bereits 802.11ac Messungen durchführen.
AirMagnet Survey kann bereits 802.11ac Messungen durchführen.
Eine Kurzübersicht der Unterschiede von 802.11n zu 802.11ac:
| 802.11n | 802.11ac | |
| Frequenzband | 2.4GHz und 5GHz | 5GHz |
| Kanalbreite | 20 und 40MHz | 20,40, 60, 80MHz (Option 160MHz) |
| Spatial Streams | 1 bis 4 | 1 bis 8 (bis zu 4 pro Client) |
| Multiple User MIMO | Nein | Ja |
| Single stream max. client data rate | 150Mb/s | 433Mb/s (bei 80MHz-Kanälen) |
19.03.2013
In der Vergangenheit stand bei Neuvorstellungen von Produkten immer die Liste der technischen Highlights im Vordergrund. Nach dem Prinzip „schneller, höher, weiter“ sollte die Menge der darstellbaren Parameter potentielle Kunden von der Qualität der Geräte überzeugen.
Doch wer als IT-Verantwortlicher möchte bzw. kann aus dieser Informationsflut letztendlich die wichtigen Informationen herausfiltern und so interpretieren, dass am Ende die Lösung des Problems steht?
Dank Vorreitern, wie z.B. Apple, die u.A. durch den Fokus auf die wichtigsten Details Marktführer im Consumer-Bereich geworden sind, achten nun auch Hersteller der IT-Messtechnik verstärkt auf die Übersichtlichkeit der Darstellung von Ergebnissen komplexer Analyseverfahren.
Das ist sicherlich sinnvoll, denn es interessiert den IT-Verantwortlichen im ersten Moment nur, ob die für den IT-Betrieb aus Anwendersicht relevanten Komponenten in gewünschter Zeit verfügbar sind. Erst dann, wenn Probleme aufgezeigt werden, möchte er sich mit den Details, die zu dem Problem geführt haben, detaillierter auseinander setzen.
Ein gutes Beispiel für die Umsetzung der vereinfachten Darstellung in der IT-Analyse sind das neue ![]() Fluke OneTouch AT oder
Fluke OneTouch AT oder ![]() GeNiEnd2End.
GeNiEnd2End.
Aus der Sicht der IT gibt es viel Skepsis gegenüber dem Hype um BYOD (Bring Your Own Device). Und ob sich diese Organisationsrichtlinie sich durchsetzen wird, ist nicht sicher. In letzter Zeit hört man immer häufiger von PUOCE (Private Use of Company Equipment) – dem umgekehrten Weg, die Mitarbeiter bekommen ein Gerät von der Firma gestellt, welches auch privat genutzt werden kann.
Unabhängig davon, welcher Hype sich jetzt durchsetzen wird, es werden neue Arbeitsmodelle entstehen, bei denen die Leistung und nicht Anwesenheit im Mittelpunkt steht. Das Verwischen der Grenzen zwischen Berufs- und Privatleben ist nicht aufzuhalten. Hierdurch ergeben sich neue Chancen und Risiken für die Unternehmen. Ganz oben auf der Liste mit den Risiken steht das Thema Netzwerksicherheit und der Schutz geschäftskritischer und vertraulicher Daten.
Um die Netzwerksicherheit zu wahren, ist es deshalb äußerst wichtig, dass BOYD und Co. auf die Netzwerkzonen begrenzt wird, in denen Sicherheitsrichtlinien anwendbar sind. Im Falle einer Sicherheitsverletzung ist die IT darüber zu alarmieren.
Um sicherzustellen, dass Endgeräten die Network Access Control Systeme oder andere Sicherheitsmechanismen nicht umgehen, sollte in Echtzeit aufgezeichnet werden, welche Endgeräten mit dem Netzwerk verbunden sind und - noch wichtiger - historisch dokumentiert werden, wo sie angeschlossen sind/waren.
An dieser Stelle wäre es wichtig und wertvoll ein System einzuführen, das in Echtzeit Sicherheitsverletzung, wie z.B. neue Geräte, ein Gerät welches sich in einer nicht-autorisierten Zone befindet oder unzulässige Netzwerkänderungen, automatisch meldet. Haben wir Ihr Interesse geweckt und wollen Sie mehr über ein solches System erfahren? Mehr Informationen dazu gibt es beim ![]() Security Auditor von Rebasoft.
Security Auditor von Rebasoft.
In den letzten Jahren ist in der IT viel „optimiert“ worden. Konsolidierungen von Rechenzentren, Outsourcing und SAAS waren u.a. dabei die Schlagworte.
In diesem Zusammenhang ist in den Unternehmen sehr häufig hauseigene Kompetenz für die Sicherstellung des Betriebes der Business-kritischen Applikationen verloren gegangen. Insbesondere sporadische Probleme mit der Applikationsperformance stellen heute alle Beteiligten vor eine große Herausforderung. Die Überwachungssysteme für den jeweiligen Zuständigkeitsbereich stehen auf „grün“, doch die Anwender klagen trotzdem über langsame Anwendungen. Je nach Wichtigkeit der Anwendung, oder häufig auch der Hierarchie der Betroffenen im Unternehmen, steigt die Dringlichkeit das Problem zu beheben.
In dieser Phase beginnt dann nicht selten das sogenannte „Finger-Pointing“. Niemand möchte den „Schwarzen-Peter“ auf dem Tisch haben und versucht seine Unschuld, mit den ihm verfügbaren Informationen zu belegen. Aus dieser Situation heraus entstehen nicht selten langwierige, aufreibende „Grabenkämpfe“, in denen sich die Fronten verhärten.
In dieser Situation kann die ![]() Unterstützung eines externen, unabhängigen „Dritten“ mehr als hilfreich sein. Unvorbelastet durch etwaige Vorgeschichten oder die Rücksichtnahme auf Empfindlichkeiten der Beteiligten kann das Problem analysiert und die Fehlerquelle zugeordnet werden. Zusätzlicher Vorteil: Ein
Unterstützung eines externen, unabhängigen „Dritten“ mehr als hilfreich sein. Unvorbelastet durch etwaige Vorgeschichten oder die Rücksichtnahme auf Empfindlichkeiten der Beteiligten kann das Problem analysiert und die Fehlerquelle zugeordnet werden. Zusätzlicher Vorteil: Ein ![]() unabhängiger Dritter ist nach der Analyse wieder aus dem Haus und sitzt nicht beim nächsten Quartalsmeeting wieder mit am Tisch. Wichtig dabei ist, dass auf das Fehlerszenario abgestimmte Analyselösungen eingesetzt werden.
unabhängiger Dritter ist nach der Analyse wieder aus dem Haus und sitzt nicht beim nächsten Quartalsmeeting wieder mit am Tisch. Wichtig dabei ist, dass auf das Fehlerszenario abgestimmte Analyselösungen eingesetzt werden.
Mit dem neuen ![]() GeNiJack plus gibt es eine neue Variante von unseren „warmen Semmeln“. Dieser GeNiJack plus bietet mit den 2 Ethernet-Ports und WLAN, neue Einsatzmöglichkeiten wie z.B. ein ferngesteuertes Packet-Tracing an einem Spiegelport. In Kombination mit der web-basierenden
GeNiJack plus gibt es eine neue Variante von unseren „warmen Semmeln“. Dieser GeNiJack plus bietet mit den 2 Ethernet-Ports und WLAN, neue Einsatzmöglichkeiten wie z.B. ein ferngesteuertes Packet-Tracing an einem Spiegelport. In Kombination mit der web-basierenden ![]() GeNiEnd2End MultiTrace Software können jetzt mehrere GeNiJacks zentral für eine Multi-Segment-Datenaufzeichnung konfiguriert werden. Die Trace-Files werden auf der enthaltenen SD-Karte abgelegt und können anschließend bei Bedarf für eine Multi-Trace-Analyse mit z.B.
GeNiEnd2End MultiTrace Software können jetzt mehrere GeNiJacks zentral für eine Multi-Segment-Datenaufzeichnung konfiguriert werden. Die Trace-Files werden auf der enthaltenen SD-Karte abgelegt und können anschließend bei Bedarf für eine Multi-Trace-Analyse mit z.B. ![]() ClearSight Analyzer von Fluke Networks analysiert werden. Mit dem GeNiJack plus gibt es jetzt eine preiswerte Detailanalyse für die Paketanalyse in Remote Lokationen und ergänzt hiermit die integrierte Ende-zu-Ende/QoS Funktionalität.
ClearSight Analyzer von Fluke Networks analysiert werden. Mit dem GeNiJack plus gibt es jetzt eine preiswerte Detailanalyse für die Paketanalyse in Remote Lokationen und ergänzt hiermit die integrierte Ende-zu-Ende/QoS Funktionalität.

Beim TCP-Protokoll stoßen Applikation und Netzwerk aufeinander und die Interaktion zwischen den beiden ermöglicht es uns die elementaren Fragen um die Applikationsperformance zu beantworten.
14.09.2012
Auch in diesem Herbst veranstaltet NETCOR seine Info-Days! Am 17.10.2012, 06.11.2012 und 07.11.2012 ist es wieder so weit: Hamburg, Stuttgart und Düsseldorf werden angesteuert Thematisch geht es auch in diesem Jahr um das Thema IT-Performance.
Zu den folgenden Themen gibt es praxisnahe Vorträge:
- Effektive Netzwerk- und Anwendungsanalyse in 1 und 10G-Netzwerken
- Security Information & Event Management (SIEM)
- Datendurchsatz vs. Latenzzeit und Paketverlust
Zwei Themen werden besonders griffig anhand von Projektberichten behandelt:
- Analyse sporadischer Performanceprobleme in Triple-Play-Netzwerken
- WLAN-Troubleshooting in 802.11 a/b/g/n basierenden Netzwerken
Natürlich gibt es auch eine ![]() ausführliche Agenda.
ausführliche Agenda.
Veranstaltungsorte sind der Flughafen Hamburg-Fuhlsbüttel, Stuttgart und Düsseldorf International. Düsseldorf ist tatsächlich ziemlich international, Stuttgart und Hamburg nicht so stark, dafür ist letzterer aber laut Skytrax der „Best Regional Airport Europe“ 2011.
Bereits im Jahr 2010 waren die NETCOR Info-Days auf einem Flughafen zu Gast. Damals hatten wir in Stuttgart allerdings nicht ganz so viel Glück. Durch die Aschewolke vom Vulkan Eyjafjallajökull (gar nicht so leicht auszusprechen...) haben wir während der Flughafentour (gibt es dieses Mal auch!) nur ein einziges sich bewegendes Flugzeug gesehen. Dafür ging es jedoch in die Flughafenfeuerwehr und wir sind in die Halle der Gepäcksortieranlage gekommen.
Statistisch ist es unwahrscheinlich, dass bei den NETCOR Info-Days 2012 erneut ein Vulkan den europäischen Flugverkehr lahmlegt und das Kabinenpersonal der Lufthansa sollte sich auch mit seinem Arbeitgeber geeignet haben. Damit steht einer jeweils sehr spannenden Tour, die die Vorträge abrundet, nichts im Wege!
Als ich mich vor 25 Jahren für eine Laufbahn in der IT-Branche entschieden habe, stand bei den Netzwerkverantwortlichen, wie auch heute noch, die Verfügbarkeit und Performance des Netzes im Fokus. Allerdings waren die damaligen X.25 Weitverkehrsnetze oder LANs auf Basis von Koaxialkabel im Vergleich zu den heutigen modernen Netzwerken fehleranfälliger. Deshalb war es seinerzeit wichtig mit den Netzwerkmanagementsystemen die Verfügbarkeit der Netzwerkkomponenten respektive –Ports zu dokumentieren. Das war die Zeit der Netzwerktopologiekarten, die mittels einer Ampeldarstellung die Verfügbarkeit visualisierten. Von den heute üblichen Verfügbarkeitszahlen konnte man damals nur träumen.
Mittlerweile sind hochverfügbare Netze Stand der Technik und werden sogar für Sprach- und Videodienste genutzt. Das war in jenen Tagen unvorstellbar und dieser technische Entwicklungsverlauf hat mit dafür gesorgt, dass das Telefonieren ins Ausland preiswert geworden ist.
Netzwerkausfälle gehören heutzutage zu den Ausnahmen. Performance hingegen ist durch die zunehmend komplexere IT-Landschaft für viele Netzwerkverantwortliche die neue Plage geworden. Dabei ist für mich wirklich unverständlich, dass die Netzwerkverantwortlichen so leidensfähig sind. Solange ich schon im IT-Geschäft unterwegs bin, bekomme ich zu hören, dass bei Performanceproblemen immer die Netzwerker schuld sind. Der technische Fortschritt ist bei den Netzwerkspezialisten angekommen, aber die gedankliche Weiterentwicklung - was die Performance betrifft -leider noch nicht. Mittels klassischen Netzwerkmanagementsystemen wird die Netzwerkleistung dokumentiert, Performancewerte der Netzwerkkomponenten und –Ports werden mittels ![]() SNMP abgefragt. Eventuell wird mittels
SNMP abgefragt. Eventuell wird mittels ![]() Netflow und/oder Paketanalyse über den möglichen Lastverursacher noch eine Detailanalyse geliefert. Leider wird hier die Performance, die beim Anwender ankommt, außer Acht gelassen. Deshalb melden auch die Anwender die Performanceengpässe und nicht die Managementsysteme.
Netflow und/oder Paketanalyse über den möglichen Lastverursacher noch eine Detailanalyse geliefert. Leider wird hier die Performance, die beim Anwender ankommt, außer Acht gelassen. Deshalb melden auch die Anwender die Performanceengpässe und nicht die Managementsysteme.
Es überrascht mich immer noch, wenn ich von Netzwerkadministratoren höre, dass sie mit den klassischen Management- und Analysentools entweder mit sehr viel Aufwand den/die Performanceverursacher ermittelt haben oder sogar aufgegeben haben. Wobei es heutzutage effizientere Ansätze gibt Performancebeschwerden zu beseitigen.
Vor Kurzem waren wir bei einem Kunden, der mit dauerhaften Performanceproblemen in einigen Filialen zu kämpfen hatte. Auch hier wurde bereits sehr viel Zeit investiert - aber ohne nennbaren Erfolg. Die vorhandenen Monitoring-Tools registrierten keine Auffälligkeiten, trotzdem beschwerten sich die Anwender in den Außenstellen über lange Antwortzeiten.
Als wir den Netzwerkverantwortlichen überzeugen konnten, dass es heutzutage einfachere Wege zur Erfassung der vorhandenen Netzwerkleistung aus Sicht des Anwenders gibt, waren sie bereit mittels ![]() GeNiEnd2End Network die Netzwerkqualität Ende-zu-Ende zu messen. Innerhalb kürzester Zeit konnte nachgewiesen werden, dass es auf der Weitverkehrsverbindung zu einigen Filialen erhebliche Paketverluste gab. Eigentlich sollte dieser schnelle Erfolg die Beteiligten erfreuen. Indessen gab es kritische Stimmen beim Kunden, die das Messprinzip in Frage gestellt haben. Nach dem Motto: So etwas „einfaches“ kann keine verlässlichen Messwerte liefern. Nachdem aber ein
GeNiEnd2End Network die Netzwerkqualität Ende-zu-Ende zu messen. Innerhalb kürzester Zeit konnte nachgewiesen werden, dass es auf der Weitverkehrsverbindung zu einigen Filialen erhebliche Paketverluste gab. Eigentlich sollte dieser schnelle Erfolg die Beteiligten erfreuen. Indessen gab es kritische Stimmen beim Kunden, die das Messprinzip in Frage gestellt haben. Nach dem Motto: So etwas „einfaches“ kann keine verlässlichen Messwerte liefern. Nachdem aber ein ![]() „Performancespezialist“ von NETCOR mittels der integrierten Packet-Trace-Funktion glaubhaft die Messergebnisse belegen konnte, akzeptierte der Kunde, dass die WAN-Verkehrsverbindungen der Verursacher, des Performanceproblems war. Das war natürlich nicht zur Freude des Netzwerkproviders.
„Performancespezialist“ von NETCOR mittels der integrierten Packet-Trace-Funktion glaubhaft die Messergebnisse belegen konnte, akzeptierte der Kunde, dass die WAN-Verkehrsverbindungen der Verursacher, des Performanceproblems war. Das war natürlich nicht zur Freude des Netzwerkproviders.
Dieses Beispiel zeigt, dass eine Ende-zu-Ende Messlösung die vorhandenen Monitoring-Tools wirkungsvoll ergänzen kann. Diese klassischen Tools - die unverzichtbar für das Netzmanagement sind - liefern die üblichen Leistungswerte, wie z.B. die genutzte Bandbreite. Wobei eine hohe Netzwerkauslastung nicht automatisch mit langen Antwortzeiten aus Sicht des Anwenders gleichzusetzen ist. Im Umkehrschluss kann es trotz geringer Auslastung lange Antwortzeiten geben. Bandbreitenunabhängig kann mit GeNiEnd2End Network innerhalb einer Minute die Ende-zu-Ende-Leistung des Netzes bewertet werden.
Deshalb, lieber Netzwerker, tue dir selber einen gefallen und gehe neue Wege mit Ende-zu-Ende Performance-Tools. Oder wie die Chinesen sagen: Besser auf neuen Wegen etwas stolpern als auf alten Pfaden auf der Stelle treten!
Qualitätssicherung, Transparenz, Endanwenderzufriedenheit. Das sind Anforderungen, deren Umsetzung im Unternehmen ohne eine Investition in die Mess- und Monitoring-Lösungen nicht realisierbar sind. Ist der Entschluss erst einmal gefasst, ein Projekt in diese Richtung zu starten, sieht sich der Projektverantwortliche bei seiner Recherche einer Vielzahl von Produkten und Anbietern gegenüber. Anhand der über das Internet zur Verfügung gestellten Informationen ist es aber kaum möglich eine objektive Bewertung der vorgestellten Lösungen vorzunehmen.
Auf dem Datenblatt können die Produkte eh fast alles und mit Schlagworten, wie „End-User-Perspektive“ oder „Ende-zu-Ende Performance Monitoring“ wird vom Marketing des Herstellers selten gegeizt. Die Grenzen bzw. Schwächen eines Produktes nennt logischerweise keiner. Aber gerade diese Informationen sind für eine Kaufentscheidung letztendlich neben dem Preis ausschlaggebend.
An dieser Stelle ist eine ![]() herstellerübergreifende, objektive Beratung wichtig und wertvoll, um mit möglichst geringem Zeitaufwand eine Art Vorselektion zu treffen, um dann zu entscheiden, in welche Lösungen weitere Zeit, z.B. in eine
herstellerübergreifende, objektive Beratung wichtig und wertvoll, um mit möglichst geringem Zeitaufwand eine Art Vorselektion zu treffen, um dann zu entscheiden, in welche Lösungen weitere Zeit, z.B. in eine ![]() Teststellung, investiert wird.
Teststellung, investiert wird.
Wieder ist eine ![]() Dienstleistung abgeschlossen. Das Problem wurde gefunden und der Kunde ist glücklich. Für den Kunden war es ein längerer Leidensweg, da die Probleme schon eine geraume Weile zwischen dem Lieferanten der Software, dem Server Betreiber, den Anwendungsbetreuern und den Netzwerkverantwortlichen verschoben wurde. Da die Umgebung auch keine simple Client zu "Single Server" Anwendung war, sondern deutlich komplexer, wählten wir den Weg des Ausschlussverfahrens. Komplex daran war: ESX Server auf 2 Blade Systemen, mit jeweils 2 virtuellen Servern und mehreren einzelnen verteilten Anwendungsdiensten. Das Ganze in einem MS Cluster, der aus VM Sicht und MS Clustersicht beliebig verteilt werden konnte. Natürlich alles doppelt redundant angeschlossen.
Dienstleistung abgeschlossen. Das Problem wurde gefunden und der Kunde ist glücklich. Für den Kunden war es ein längerer Leidensweg, da die Probleme schon eine geraume Weile zwischen dem Lieferanten der Software, dem Server Betreiber, den Anwendungsbetreuern und den Netzwerkverantwortlichen verschoben wurde. Da die Umgebung auch keine simple Client zu "Single Server" Anwendung war, sondern deutlich komplexer, wählten wir den Weg des Ausschlussverfahrens. Komplex daran war: ESX Server auf 2 Blade Systemen, mit jeweils 2 virtuellen Servern und mehreren einzelnen verteilten Anwendungsdiensten. Das Ganze in einem MS Cluster, der aus VM Sicht und MS Clustersicht beliebig verteilt werden konnte. Natürlich alles doppelt redundant angeschlossen.
Wir setzten ![]() GeNiEnd2End Application ein, um die sporadischen von den Anwendern beschriebenen Probleme sichtbar zu machen. Des Weiteren nutzen wir
GeNiEnd2End Application ein, um die sporadischen von den Anwendern beschriebenen Probleme sichtbar zu machen. Des Weiteren nutzen wir ![]() GeNiEnd2End Network, um die Netzwerk Infrastruktur aus Sicht der Ende-zu-Ende Qualität zu betrachten.
GeNiEnd2End Network, um die Netzwerk Infrastruktur aus Sicht der Ende-zu-Ende Qualität zu betrachten.
Wie meistens üblich, ist es selten ein einziges großes Problem, sondern es sind viele kleine Probleme, die ein Problem groß werden lassen.
So stellte sich heraus, dass die Anwendung in der Tat sporadisch deutlich längere Transaktionszeiten aufwies. Aber auch das Netzwerk war nicht fehlerfrei. Die zentrale WAN Strecke wies Paketverluste auf. Außerdem kam die gemessene Anwendungstransaktion ins Stocken, weil lokale sowie remote angebundene Arbeitsplätze durch nur 1-2 verlorene Pakete statt einer Sekunde 2,5 Sekunden brauchten.
Die WAN Strecke wurde durch neue Router getuned, was zu einer deutlichen Verbesserung der nutzbaren Bandbreite, aber auch zum Wegfall aller Paketverluste führte.
Um die Ursache und den Ort der Paketverluste im LAN weiter einzuschränken wurde ![]() GeNiEnd2End Multitrace eingesetzt. Damit war es nun sehr einfach möglich eine 3 Punkt Zangenmessung auszuführen und eine Problem-Transaktion zu untersuchen. Die Zangenmessung wurde auf dem VM Gast, am Serverswitch via SPAN und am Client aufgesetzt. Die Untersuchung ergab, dass die Pakete zwischen Serverswitch und VM Gast verloren gingen.
GeNiEnd2End Multitrace eingesetzt. Damit war es nun sehr einfach möglich eine 3 Punkt Zangenmessung auszuführen und eine Problem-Transaktion zu untersuchen. Die Zangenmessung wurde auf dem VM Gast, am Serverswitch via SPAN und am Client aufgesetzt. Die Untersuchung ergab, dass die Pakete zwischen Serverswitch und VM Gast verloren gingen.
Diese Verluste wurden auch durch die Messung mit GeNiEnd2End Network bestätigt. Hier waren ebenfalls Paketverluste über den ganzen Zeitraum der Messung zwischen Serverswitch und vServer messbar.
Es folgten nun einige Versuche der Serverleute das Problem weiter einzugrenzen. Die Kontrolle oblag jetzt nur noch ![]() GeNiEnd2End Network und
GeNiEnd2End Network und ![]() GeNiEnd2End Application – durch diese Tools erhielten wir eine Analyse mit nur minimalen Aufwand im einstelligen Minutenbereich! Alle Änderungen, z.B. vMotion nutzen, um das andere Blade zu testen oder Switch innerhalb des MS Clusters, brachten leider keinen Erfolg.
GeNiEnd2End Application – durch diese Tools erhielten wir eine Analyse mit nur minimalen Aufwand im einstelligen Minutenbereich! Alle Änderungen, z.B. vMotion nutzen, um das andere Blade zu testen oder Switch innerhalb des MS Clusters, brachten leider keinen Erfolg.
Letztendlich gelang eine Besserung durch den Tausch der virtuellen Netzwerkkarte innerhalb des VM Gastes.
Die Messungen zeigten nun, dass durch diese Änderung keine Verluste von Paketen innerhalb der VM mehr auftraten.
Somit wurde dieses Problem mit vergleichbar wenig Aufwand identifiziert und schlussendlich in der richtigen Abteilung behoben.
Sie kennen es sicherlich: die WLAN-Verbindung reißt ab und meist weiß man nicht, warum dies gerade geschehen ist.
Schlechter Empfang? Roaming von AP zu AP? Stört etwas die WLAN-Verbindung?
Manches kann man von Haus aus leicht erkennen, wie z.B schlechten Empfang, anderes aber nicht, wie Störquellen (WLAN-fremde Geräte), die das Signal beeinträchtigen.
Wie findet man nun also heraus, was gerade das WLAN-Signal beeinträchtigt und wo es sich befindet?
Das Tool ![]() AirMagnet Spectrum XT zeigt Störquellen auf, identifiziert sie und bietet Ihnen die Möglichkeit diese zu lokalisieren. Natürlich in allen WLAN-Frequenzbereichen und mit Messadapter auf USB-Basis. Zur Darstellung der Auswirkungen auf die WLAN-Umgebung gibt es integrierte WLAN Analyse Charts.
AirMagnet Spectrum XT zeigt Störquellen auf, identifiziert sie und bietet Ihnen die Möglichkeit diese zu lokalisieren. Natürlich in allen WLAN-Frequenzbereichen und mit Messadapter auf USB-Basis. Zur Darstellung der Auswirkungen auf die WLAN-Umgebung gibt es integrierte WLAN Analyse Charts.
Die Identifikation von Geräten geht von Bluetooth bis Zigbee und es ist möglich, eigene Signalidentifikationen zu hinterlegen.
Sofern Sie selber kein Know-How zum Thema Spectrum Analyse aufbauen wollen oder punktuell Unterstützung beim Lösen von WLAN-Problemen benötigen, stehen wir Ihnen mit Dienstleistungen und Schulungen zur Seite.
Am 27.09. und 29.09. ist es wieder so weit: NETCOR veranstaltet seine Info-Days! Dieses Mal gastieren wir im Audi Forum Neckarsulm, in Hamburg sind wir im Madison Hotel und im Miniatur Wunderland.
Thematisch steht das Thema IT-Performance im Vordergrund:
- WLAN-Troubleshooting in 802.11 a/b/g/n basierenden Netzwerken
- Portmultiplikatoren für Analyse- und Monitoring-Systeme
- Lokalisieren von Performanceproblemen in VoIP- und Datenanwendungen
- Netzwerk- und Applikationsperformanceanalyse in 1 und 10G-Netzwerken
- Analyse sporadischer Performanceprobleme in virtuellen Umgebungen
Natürlich gibt es auch eine ![]() ausführliche Agenda. Das Rahmenprogramm ist ziemlich spannend: In Neckarsulm schauen wir uns die Fertigung des Audi R8 an. Dieser beeindruckende Sportwagen verdreht mir bereits auf der Straße den Kopf – auf den Info Days kann aber jeder Teilnehmer dem Wagen ganz, ganz nahe kommen und aus der Nähe schmachtend anschauen. Sollten Sie dabei verliebt seufzen, keine Sorge, wir erzählen absolut niemandem von Ihren Gefühlen für dieses Automobil.
ausführliche Agenda. Das Rahmenprogramm ist ziemlich spannend: In Neckarsulm schauen wir uns die Fertigung des Audi R8 an. Dieser beeindruckende Sportwagen verdreht mir bereits auf der Straße den Kopf – auf den Info Days kann aber jeder Teilnehmer dem Wagen ganz, ganz nahe kommen und aus der Nähe schmachtend anschauen. Sollten Sie dabei verliebt seufzen, keine Sorge, wir erzählen absolut niemandem von Ihren Gefühlen für dieses Automobil.
Beim Miniatur Wunderland Hamburg gibt es eine Führung. Anders als gewöhnlich wird nicht die Anlage aus Besuchersicht gezeigt, nein, es gibt eine neue Sichtweise: Wir schauen uns die Technik an, die hinter der sehr detaillierten Nachbildung zahlreicher Landschaften, Städte und Infrastrukturen steckt. Jeder, der sich ein bisschen für Details und clevere Lösungen begeistern kann, wird jede Menge Spaß haben.
02.08.2011
Immer komplexer werdende Infrastrukturen mit zentral gehosteten Anwendungen machen die Suche nach evtl. Performanceengpässen zu einer zeitintensiven Aufgabe, die meist dann notwendig wird, wenn aufgrund der aktuellen Projektlage eigentlich eh keine Zeit dafür ist.
Gerade die Netzwerkverantwortlichen sind dabei in erster Linie gefordert. Die Aussage „Das Netzwerk ist mal wieder langsam!“ hat sich in den Köpfen der Anwender eingebrannt. Objektiv betrachtet gab es in den vergangenen Jahren eine eindeutige Verlagerung der Problemverursacher. Doch der Mensch bleibt gern bei dem, was ihm vertraut ist. Also ist eben erst einmal das Netzwerk schuld, bis das Gegenteil bewiesen wurde.
Auf der Suche nach möglichen Fehlerquellen bedient sich der Netzwerker typischer Weise SNMP- oder NetFlow Monitoring-Lösungen. Doch muss dabei vorab erst einmal verifiziert werden, welchen “Weg“ die Anwendung nimmt, was nicht immer einfach ist. Zudem muss ein Port mit hoher Last nicht gleich der Auslöser für hohe Antwortzeiten sein.
Auch zeitaufwendige Protokollanalyse ist ein häufig gewähltes Mittel, um den Fehler aufzudecken oder zumindest die eigene „Unschuld“ am Problem nachzuweisen. Wer sich damit schon einmal länger beschäftigt hat, weiß wie zeitintensiv das ist. Umso ärgerlicher ist es dann, wenn sich dabei herausstellt, dass das Problem gar nicht im Netz liegt!
Aus diesem Umstand heraus implementieren mehr und mehr Netzwerkverantwortliche eine Lösung, die die Performance der Infrastruktur 24x7 aus Sicht der Anwender misst und dokumentiert. Mit dem richtigen Tool kann dann innerhalb von wenigen Minuten be- oder wiederlegt werden, dass das Problem in der Infrastruktur liegt oder nicht. Eine schnell zu implementierende und bezahlbare Lösung dafür ist zum Beispiel ![]() GeNiEnd2End-Network.
GeNiEnd2End-Network.
Packets, Packets und noch einmal Packets. Alles dreht sich bei der nChronos-Software von Colasoft um die verteilte Langzeitdatenspeicherung von Datenpaketen für die forensische Netzwerkanalyse.
Über einen bewährten Workflow können nachträglich die gesammelten Datenpakete für die Identifizierung von Fehlerquellen mittels des integrierten Paketanalyzers oder auch mit Wireshark analysiert werden.
Nicht jeder kennt nChronos, aber das wird sich schnell ändern, weil im Vergleich zu den üblichen Anbietern von retrospektiven Appliance-Lösungen hat nChronos ein aggressiveres Preis/Leistungsverhältnis.
Weitere Informationen gibt es auf der Produktseite und eine Testversion kann ![]() hier auch gedownloadet werden.
hier auch gedownloadet werden.
Im aktuellen  c´t Magazin gibt es es einen neuen Artikel aus der Serie "Tatort Internet“.
c´t Magazin gibt es es einen neuen Artikel aus der Serie "Tatort Internet“.
Das Forum eines Online-Spiels wird in dem vorliegenden Fall heftig mit einer SYN-Flut attackiert.
In Folge dessen quittiert der Server fast vollständig den Dienst. Ärgerlich und auch schnell teuer: Da Forum und das eigentliche (kostenpflichtige Abo-) Spiel miteinander kommunizieren, ist auch der Spielbetrieb gestört.
Sehr anschaulich wird beschrieben, wie der Administrator zuerst mit Nagios und dann sehr energisch mit Wireshark dem Quell des Übels auf die Schliche kommt.
Letztlich wird der Angreifer isoliert, lokalisiert und von Scotland Yard in die Mangel genommen. Der Täter legt ein Geständnis ab.
Einen kleinen Makel hat diese kriminalistische Sternstunde jedoch: Der Angreifer, ein trotziger Schüler, hat sich offensichtlich keinerlei Mühe gegeben seine Identität zu verschleiern...
Falls Sie nun auf den Geschmack der Protokollanalyse gekommen sein sollten: Schauen Sie sich doch mal die Details zu unseren ![]() Wireshark-Schulungen an.
Wireshark-Schulungen an.
Unsere Schulungen sind gespickt mit Praxisbeispielen - vorerst jedoch ohne Scotland Yard.
Herzlich Willkommen im offiziellen Blog von NETCOR! Fragen Sie sich, wofür das gut sein soll? Kann ich gut nachvollziehen, so ging es einigen Kollegen zuerst auch. Allerdings hat so ein Blog jede Menge Vorteile.
An dieser Stelle möchten wir Sie immer dann informieren, wenn es etwas Neues zum Thema IT-Performance gibt. Das können Anwenderberichte, Erfahrungsberichte, neue Produkte, Tipps & Tricks für Netzwerkanalysen aber auch unsere Info-Days sein.
Also alles Themen bei denen wir Sie an unserer ![]() Kompetenz in IT-Performance teilhaben lassen wollen.
Kompetenz in IT-Performance teilhaben lassen wollen.
Via RSS können Sie sich automatisch auf dem Laufenden halten. Einfach oben auf die Schaltfläche abonnieren klicken und Sie erhalten Neuheiten aus diesem Blog automatisch. Der dafür benötigte RSS-Reader ist z.B. in IBM Lotus Notes und Apple Mail bereits integriert. Natürlich gibt es auch zahlreiche alternative Tools für Desktop und mobile Plattformen.
Wenn Ihnen danach ist, können Sie Ihre Follower über die entsprechende Schaltfläche via Twitter informieren.
Falls Sie Anregungen oder Wünschen zum NETCOR-Blog haben, melden Sie sich gern bei uns.
Nun aber wünsche ich Ihnen viel Spaß beim Lesen!
 +49 4181 9092-01
+49 4181 9092-01
{kind=link}